Puppeteer: click an element and get raw JSON from XHR/AJAX response

Table of Contents
This lately became a pretty popular question when scraping with Puppeteer: let's say you want to interact with the page (e.g. click the button) and retrieve the raw ajax response (usually, JSON). Why would you want to do this? This is actually an interesting "hybrid" approach to extracting data from the web page - while we interact with the page like a real browser, we still do not mess around with the usual DOM traversing process to extract the data, and we grab raw JSON server response instead. This might save a lot of time, especially if the website has obscure CSS classes and each data item contains a lot of small chunks of data (fields), so grabbing all these fields/properties via CSS/XPath selectors might make the extraction process rather time consuming and pretty flaky. Getting raw JSON means we don't need to do the extraction job, it's already done for us! Retrieving raw JSON from AJAX request via Puppeteer is not too hard to do, but this requires basic understanding how async programming works in JS and how we can use it in Puppeteer / Playwright.
I won't go through Puppeteer setup/installation, hopefully you have figured this step already.
Step #1. Build a good test page.
I have built a very simple test page with the button which triggers ajax request, which retrieves a sample "search results" response in JSON format, from my remote server.
https://apiroad.net/ajax-test.html
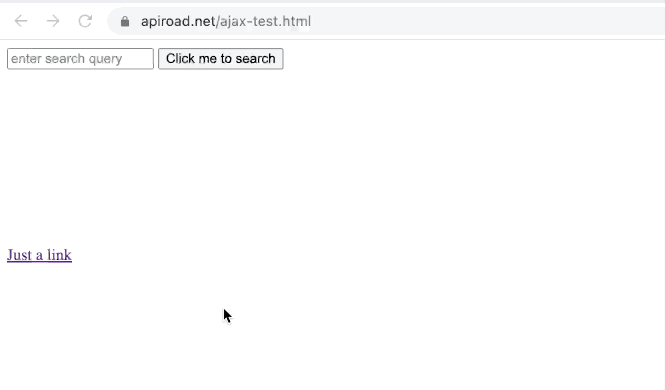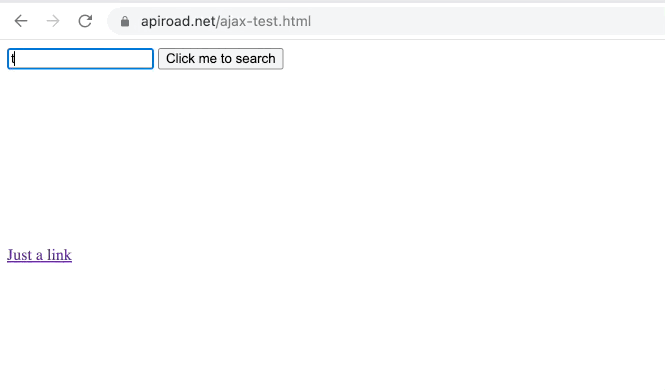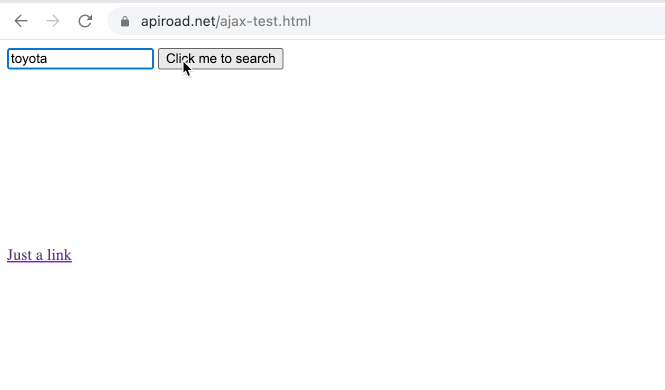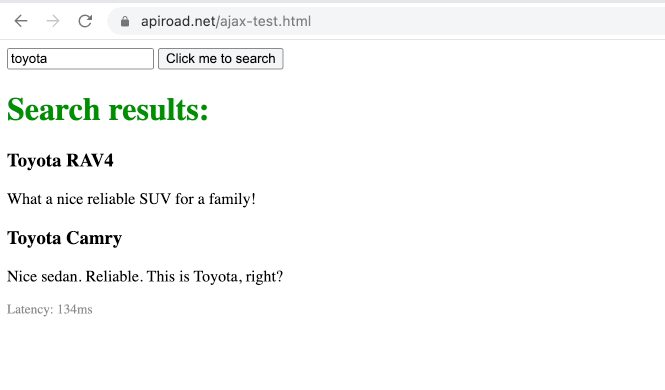
It is very important to have a simple test page where you can quickly run your experiments, so every test run takes very little time, otherwise each iteration of debugging becomes painful.
Step #2. Create puppeteer instance and click the button
import puppeteer from 'puppeteer';
(async () => {
const browser = await puppeteer.launch({args: [
'--no-sandbox']});
const page = await browser.newPage();
await page.goto('https://apiroad.net/ajax-test.html');
// let's make a screenshot to debug if the page looks good
await page.screenshot({path: 'step1.png'});
// now make sure the search input is there on the page.
await page.waitForSelector('form > input[type=text]');
// type the search query.
await page.type('form > input[type=text]', 'toyota');
await page.click('#search-button');
await page.screenshot({path: 'step2.png'});
await browser.close();
})();The "regular" approach in Puppeteer scraping world would be to do $$eval now and grab the search results elements data from DOM tree. We could definitely do that! But grabbing the raw JSON response of search results instead may make things a lot cleaner and easier for later analysis.
Step #3. Figure out which response Chrome sends to the server
I always prefer to use a real Chrome on my Mac, to see what happens under the hood, before I convert this logic into puppeteer code. Let's do this!
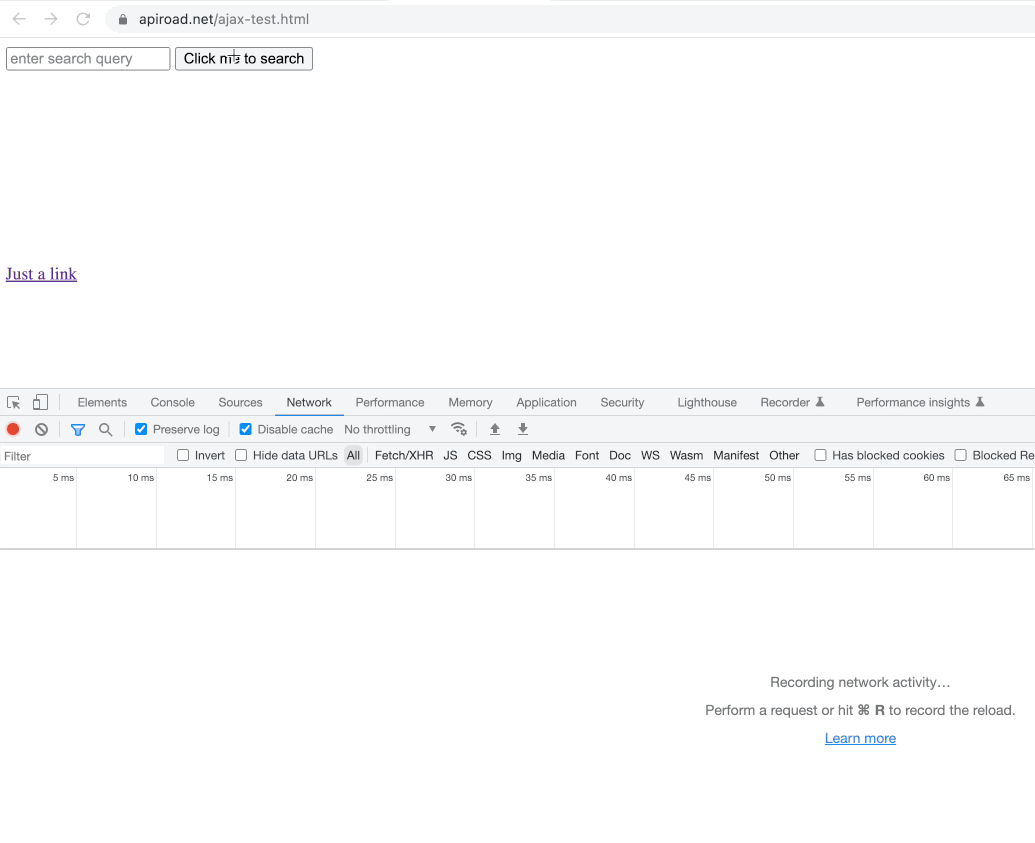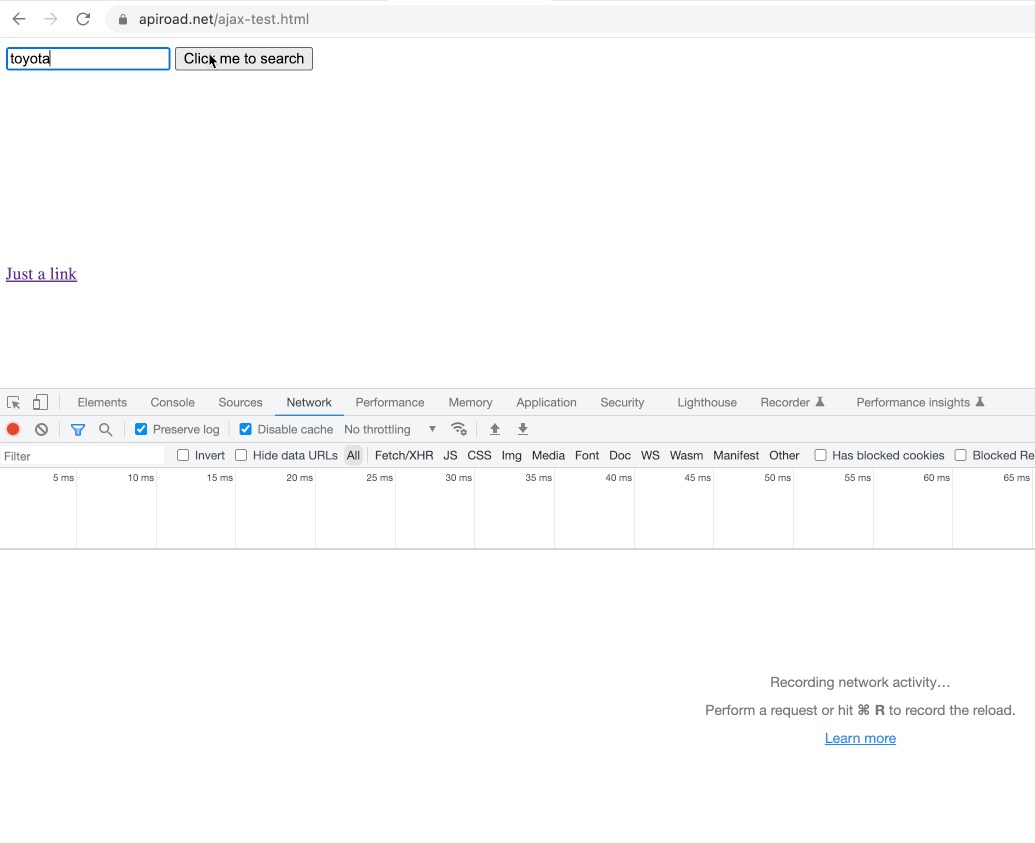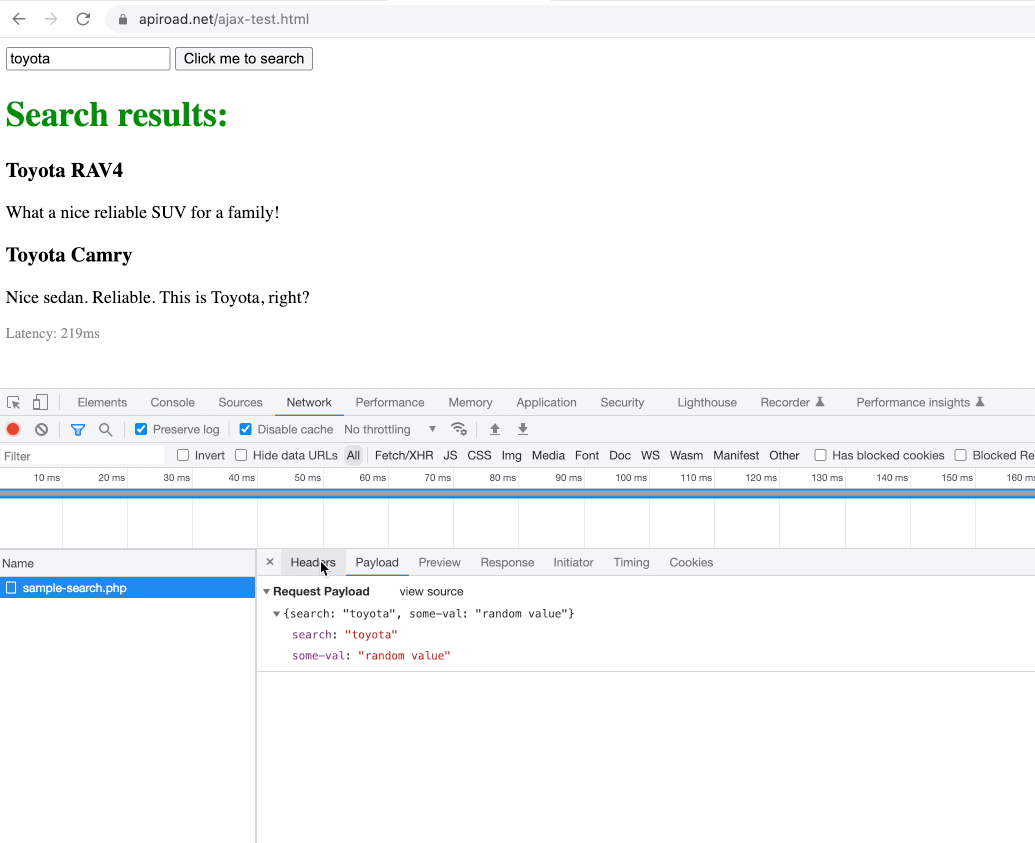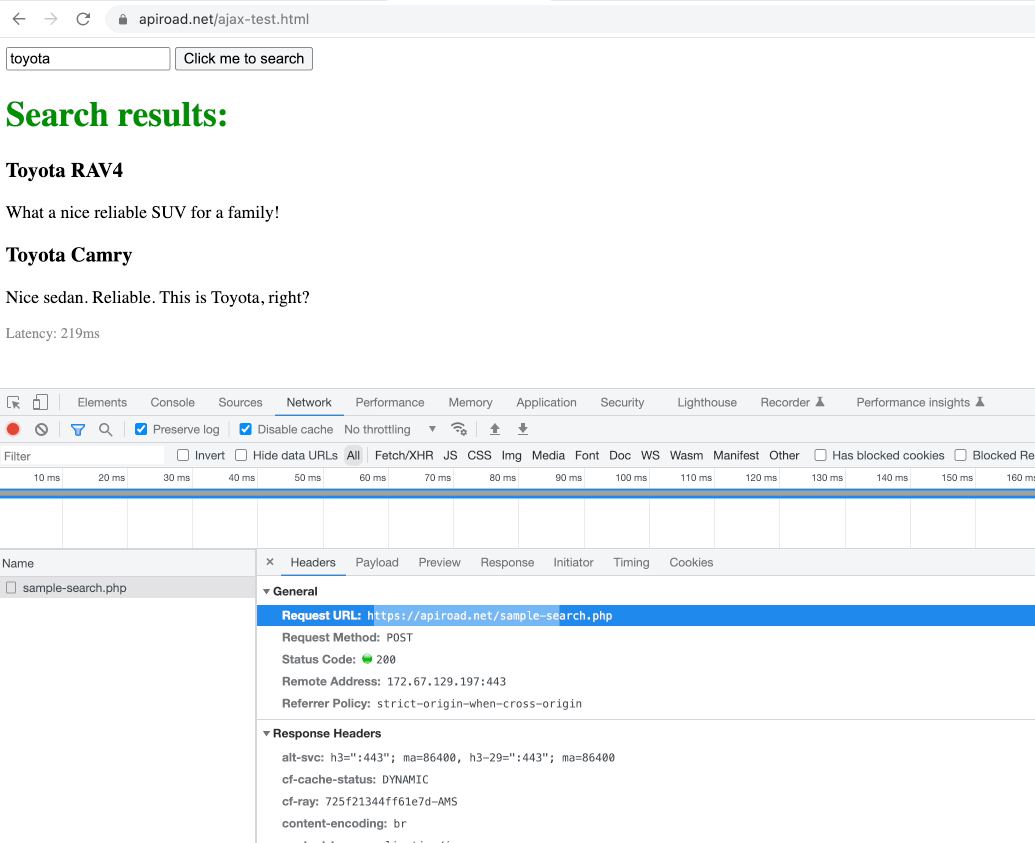
Open Chrome Dev Tools before you click the search button, then click the button, and find the ajax request which the browser has sent. We will need to put the last part of the search url to our script.
If you don't know what Chrome Dev Tools is, definitely read about this must-have tool in my previous post.
Step #4. Wait for XHR response via Puppeteer
Okay, now comes the main part – how do we make Puppeteer wait for the ajax response?
page.waitForResponse puppeteer function will do all the heavy-lifting, we just need to pass a proper callback into it, which will filter and catch the required response.
Technically what we want to do is to first let Puppeteer know that we will be waiting for JSON response, in advance, and then click the search button. This is done using creating a JS promise before the click, and then awaiting for the event of new response after we have clicked the button.
import puppeteer from 'puppeteer';
(async () => {
const browser = await puppeteer.launch({args: [
'--no-sandbox']});
const page = await browser.newPage();
await page.goto('https://apiroad.net/ajax-test.html');
await page.screenshot({path: 'step1.png'});
await page.waitForSelector('form > input[type=text]');
await page.type('form > input[type=text]', 'toyota');
// create the promise to wait for the AJAX response
// notice we do not "await" here. we just create the promise.
// also notice how we pass a filtering callback to waitForResponse() to wait for proper URL
let xhrCatcher = page.waitForResponse(r => r.request().url().includes('sample-search.php') && r.request().method() != 'OPTIONS');
page.click('#search-button');
// and now we wait for the AJAX response!
let xhrResponse = await xhrCatcher;
// now get the JSON payload
let xhrPayload = await xhrResponse.json();
console.log('xhrPayload', xhrPayload);
await page.screenshot({path: 'step2.png'});
await browser.close();
})();Note the callback for the ajax url contains additional check && response.request().method() != 'OPTIONS' which helps in case there is a pre-flight request which browser might send to check CORS access. We don't to catch this one, we need to catch the real POST request which returns actual JSON.
Running Puppeteer for scraping, in production
Running Puppeteer in production is a pretty complex endeavor. Since the moment when I have started doing scraping with real browsers, I was spending a lot of time on setting Puppeteer, setting proper user agents, proxy rotation, retries, and testing all these async interactions with web pages. I was dreaming about a beautiful and clean API which allows me to interact with web pages, and extract all the required data, but without dealing with Puppeteer verbosity, exceptions, and other painful cons.
And after weeks of development I was happy to deploy and start using my own API which runs real Chrome browser, ready for scraping, with proxies and retries already built in.
So here is the alternative of the code above, via ScrapeNinja API:
import fetch from 'node-fetch';
const url = 'https://scrapeninja.p.rapidapi.com/scrape-js';
const PAYLOAD = {
"url": "https://apiroad.net/ajax-test.html",
"method": "GET",
"retryNum": 1,
"geo": "us",
"js": true,
"blockImages": false,
"blockMedia": false,
"steps": [
{
"type": "change",
"selector": "#q",
"value": "toyota"
},
{
"type": "click",
"selector": "#search-button",
"waitForXhrRequest": "sample-search.php"
}
]
};
const options = {
method: 'POST',
headers: {
'content-type': 'application/json',
// get your key on https://rapidapi.com/restyler/api/scrapeninja
'X-RapidAPI-Key': 'YOUR-KEY',
'X-RapidAPI-Host': 'scrapeninja.p.rapidapi.com'
},
body: JSON.stringify(PAYLOAD)
};
try {
let res = await fetch(url, options);
let resJson = await res.json();
// Basic error handling. Modify if neccessary
if (!resJson.info || ![200, 404].includes(resJson.info.statusCode)) {
throw new Error(JSON.stringify(resJson));
}
console.log('target website response status: ', resJson.info.statusCode);
console.log('target website response body: ', resJson.body);
} catch (e) {
console.error(e);
}
ScrapeNinja handles all the exceptions, timeouts, retries, and proxy rotation properly, and does not leave traces that this is a browser controlled by Puppeteer - it looks like a real browser to the target website!
All the JSON dumping instructions are located in a step of click interaction:
{
"type": "click",
"selector": "#search-button",
"waitForXhrRequest": "sample-search.php"
}
and the catched XHR response will be available for you in the JSON response of ScrapeNinja server.
Isn't it beautiful?
You can run the example above from the ScrapeNinja sandbox, right in your browser:
https://scrapeninja.net/scraper-sandbox
(click the "Click & dump JSON" example in the form )