How to web scrape Zillow using ScrapeNinja and JavaScript
Table of Contents
Web scraping is a popular technique that allows developers to quickly and easily extract data from websites. It's especially useful for extracting real estate information, such as property listings and median home prices. In this blog post, we'll explore how to web scrape Zillow with low-code platform ScrapeNinja and JavaScript.
Table of contents:
- Why ScrapeNinja?
- The approach
- Prerequisites
- Choosing scraping strategy
- Switching proxy country of web scraper
- Switching to heavier Javascript Puppeteer API of ScrapeNinja
- Bypassing captcha by enforcing ScrapeNinja proxy rotation
- Writing JavaScript extractor to get data from HTML
- The result
- Running the scraper on remote Linux server
- Running ScrapeNinja scraper without remote server: Make.com
Zillow is an online real estate marketplace that houses a wealth of property data. It provides detailed information on all the homes listed in the U.S., including home values, photos, mortgage rates, and more. This data can be incredibly valuable for developers who need to analyze the market or build a real estate-related application.
Why ScrapeNinja?
I used to build web scrapers from scratch, using server-side JavaScript, but now I mostly use my JavaScript to call ScrapeNinja instead, for a good reason: I am lazy and I hate repetitive tasks.
ScrapeNinja is a swiss-army tool for web scraping. It is an API-first SaaS and it has lots of features and saves hours and hours on tedious tasks related to web scraper development: choosing proxy provider (high quality proxies are included with all ScrapeNinja plans, even free plan!), proxy rotation, ScrapeNinja allows to choose proxy pools from various countries, it sports various website scraping protection bypass techniques, smart retries, and convenient online web scraping sandbox which allows to create and test your web scraper, and when you are happy with the results - generate code for it so the scraper runs on your server, without leaving your browser.
The approach
I am going to use online web scraper builder of ScrapeNinja, and then after I test everything out, I will copy&paste the generated JavaScript scraper to my cloud server hosted on Hetzner Cloud.
JavaScript is one of the best languages for web scraping. It's easy to learn and use, it's generally gives higher performance than Python (which I also love), and it has many libraries that make it even easier to get started. Furthermore, JavaScript can be used to easily access web pages like Zillow, which makes web scraping a breeze, especially when backed by ScrapeNinja.
Prerequisites
To build and test web scraper, you need only a browser.
To launch the built web scraper on your server, you'll need to have Node.js (which is a JavaScript-based server-side platform), installed. You will also need ScrapeNinja subscription (free plan available).
Choosing scraping strategy
Let's try to scrape this page and extract property listing details, such as number of bedrooms, bathrooms, Zillow description, and property images:
https://www.zillow.com/homedetails/1930-S-River-Dr-W805-Portland-OR-97201/2078637838_zpid/
First of all, I try most basic ScrapeNinja setup - I just enter the url I want to scrape into ScrapeNinja url textfield:
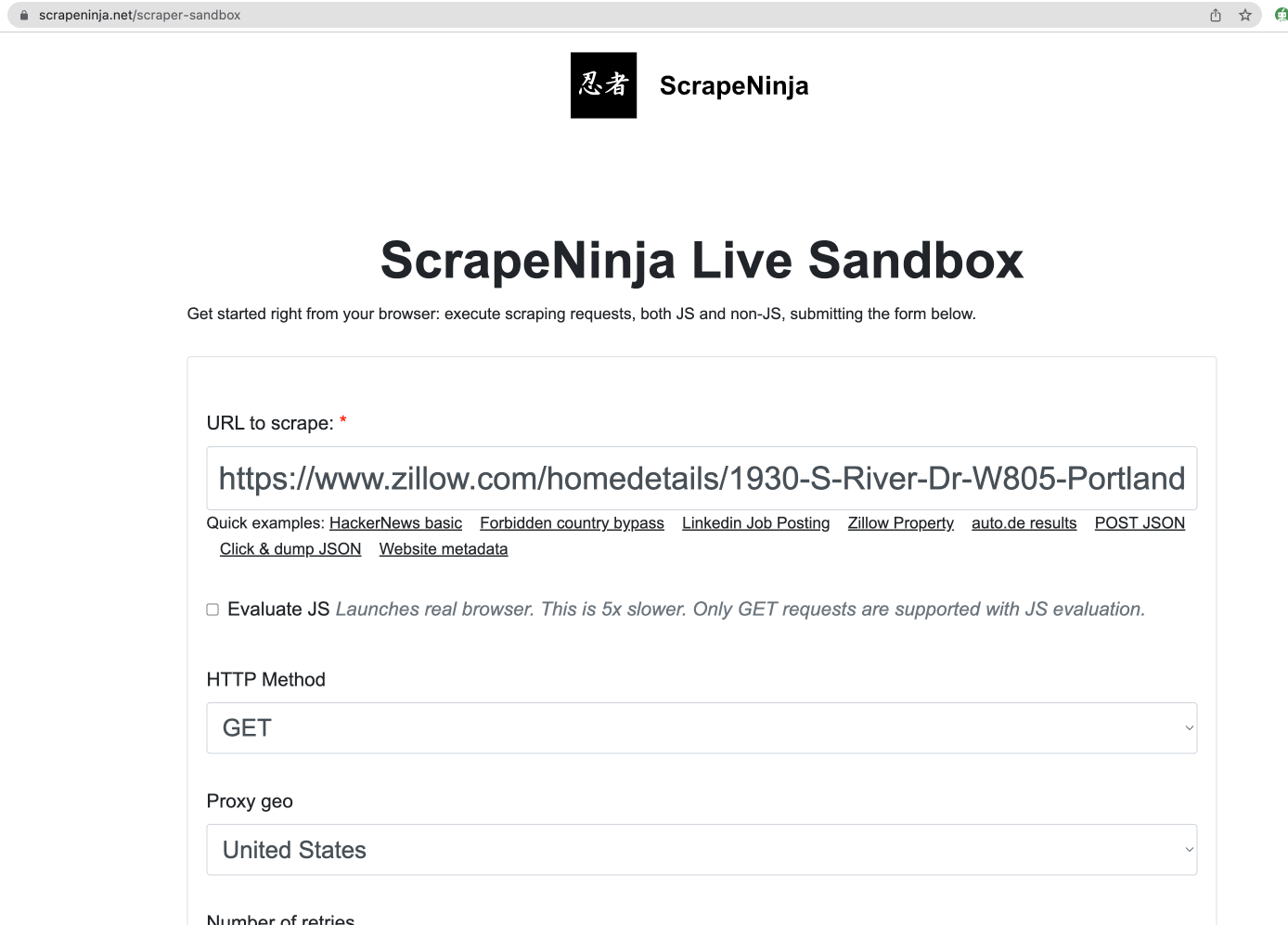
After I click big "Scrape" button, I get 403 response:
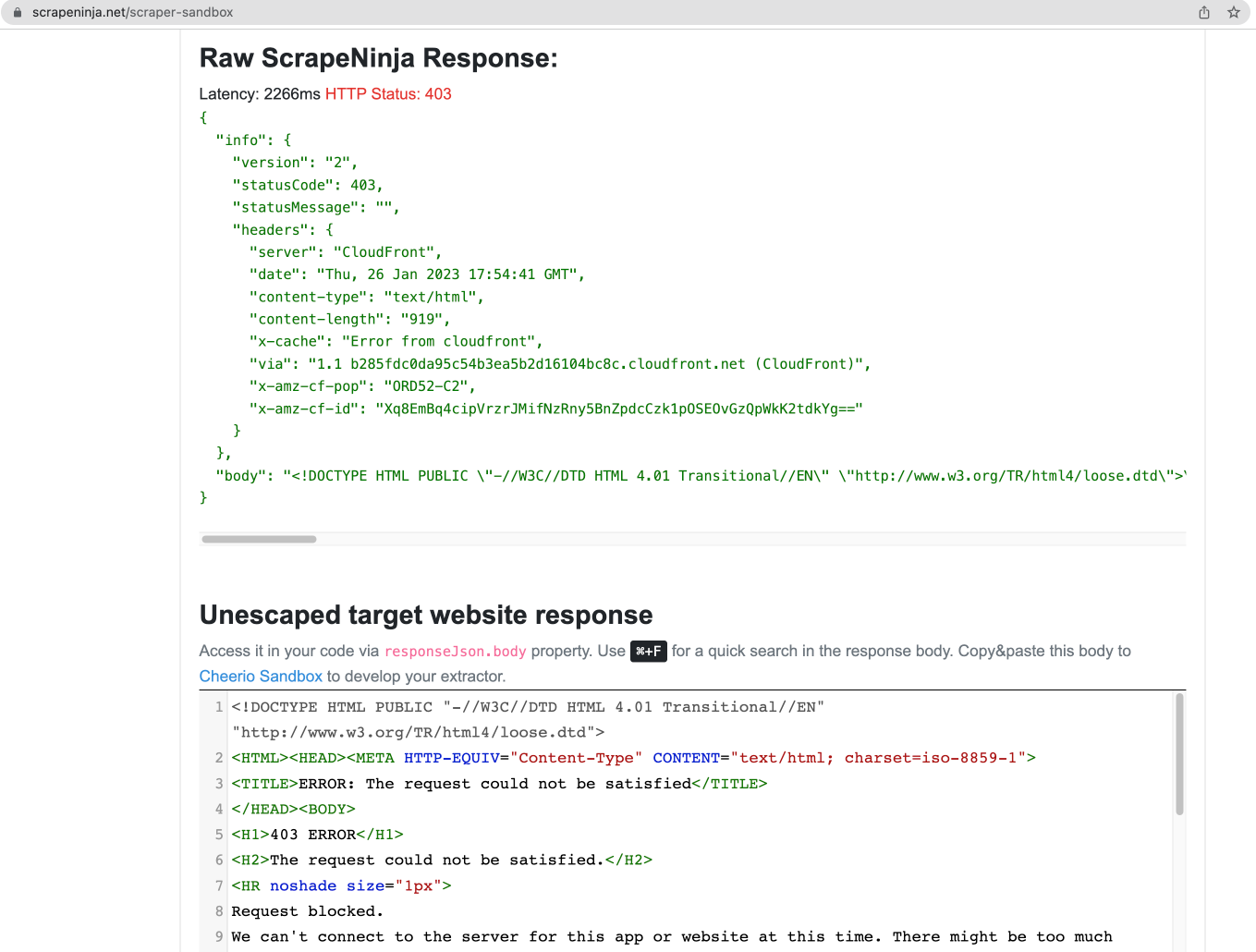
Apparently, Zillow is a heavily protected website, so we will use heavy tools to extract the data!
Switching proxy country of web scraper
To experiment, I switch "Proxy geo" to "Germany" and get better results:
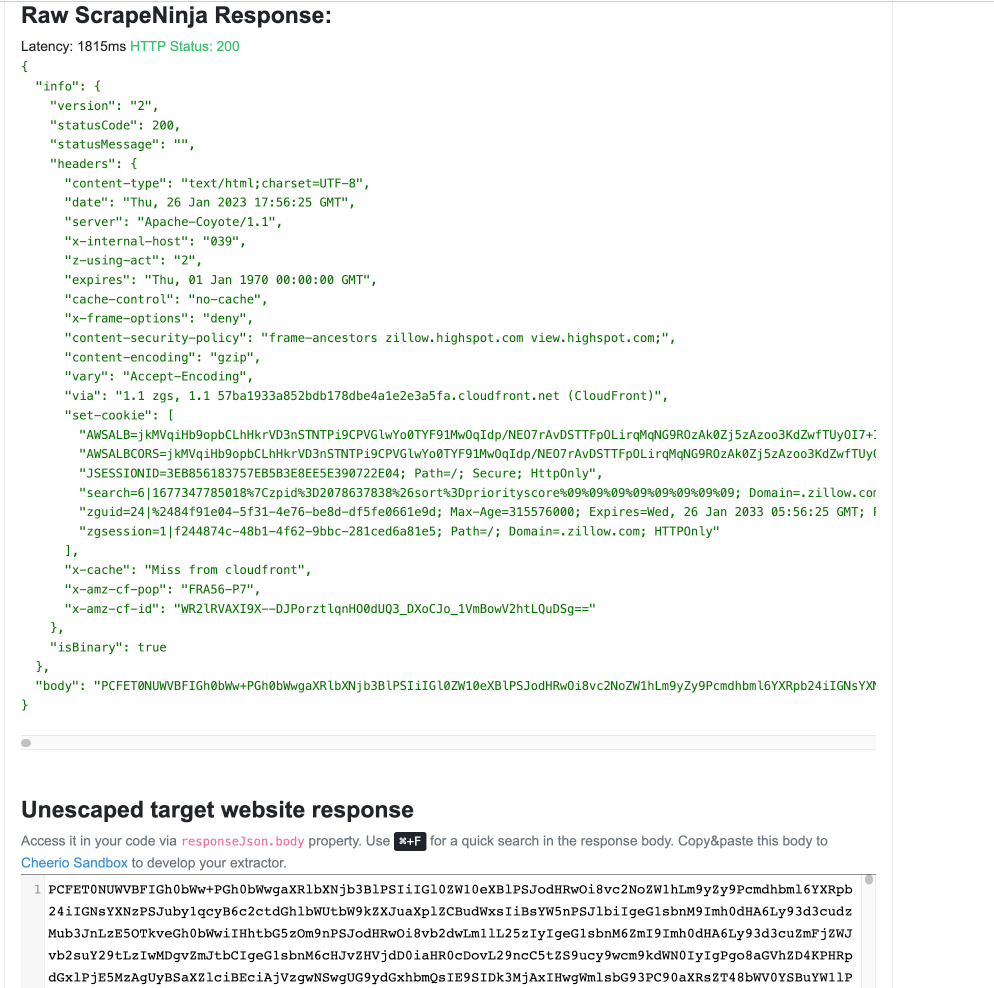
But it is still not good - instead of regular <html><body></body></html> I get some weird obfuscated string of characters in "unescaped target website response" field.
Switching to heavier Javascript Puppeteer API of ScrapeNinja
It's time for heavier tools, let's leverage another ScrapeNinja backend, by checking "Evaluate JS" checkbox, this will launch full fledged programmatically controlled browser run by Puppeteer and will render Zillow like real computer:
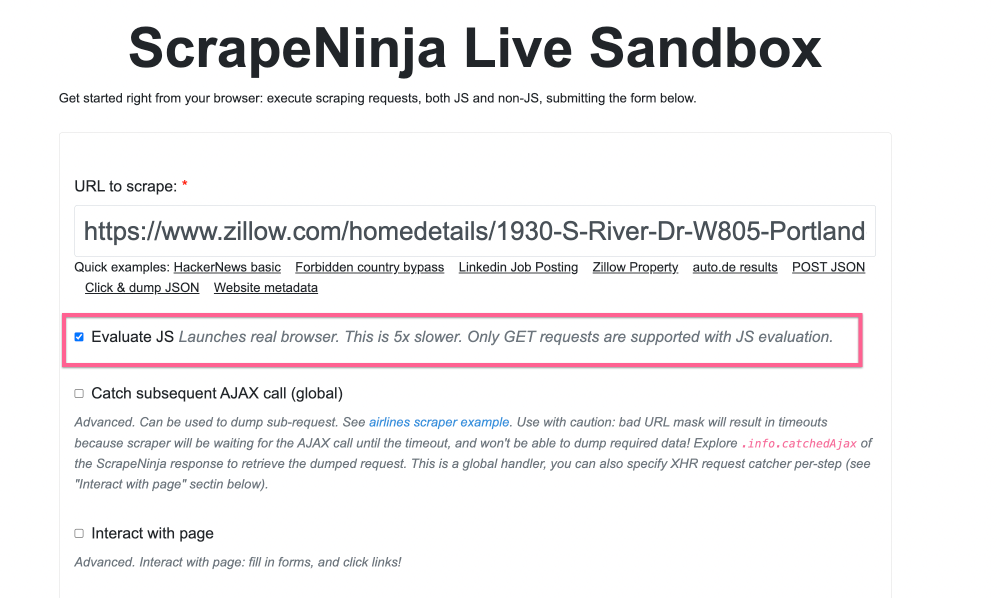
I also quickly explore HTML of the Zillow page using Chrome Dev Tools, and find some div selector which I tell ScrapeNinja to appear before returning the HTML source of the page:
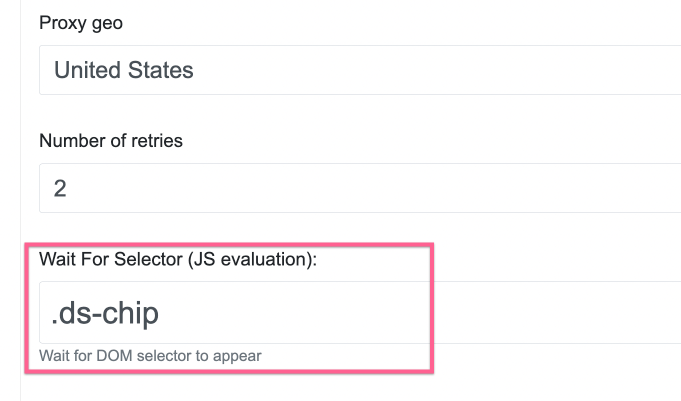
Now the ScrapeNinja results are returning real HTML of Zillow:
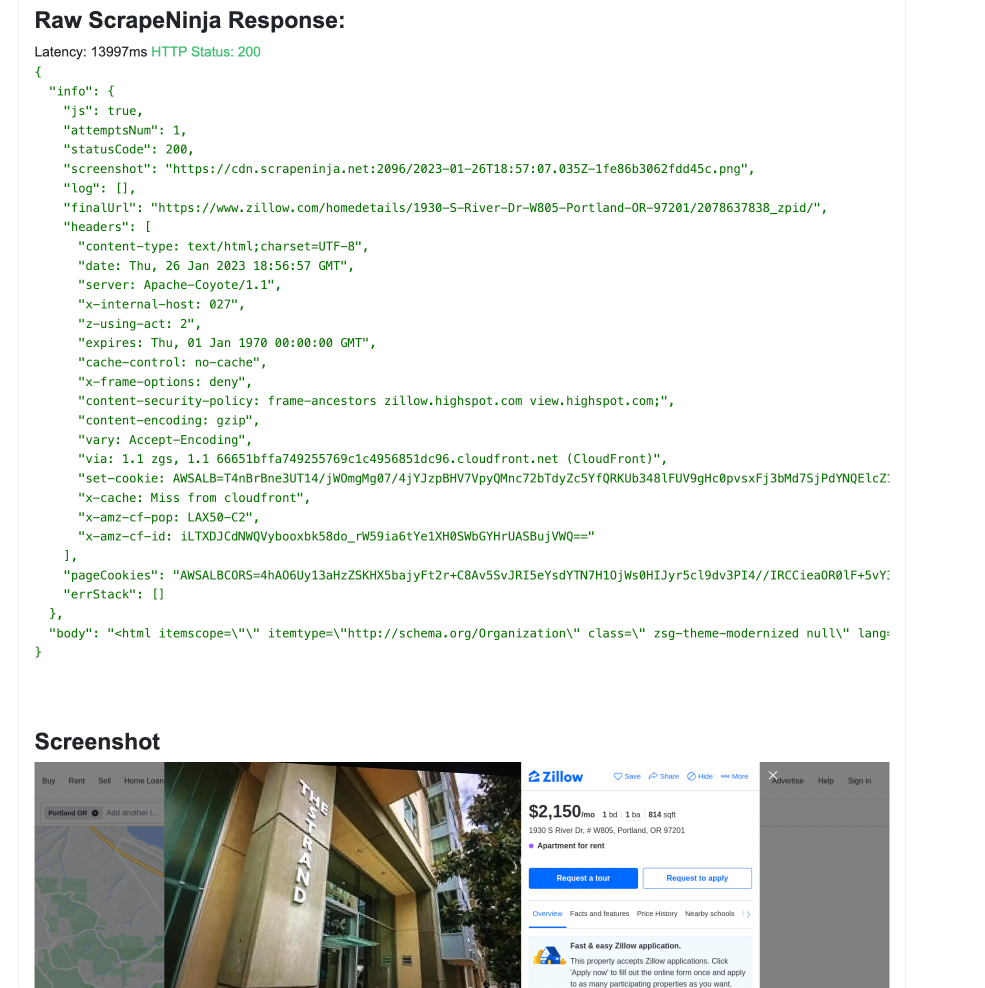
Nice side effect of "Evaluate JS" checkbox and running heavier rendering engine is that now we can also see the screenshot of the rendered page, which helps when debugging the web scraper.
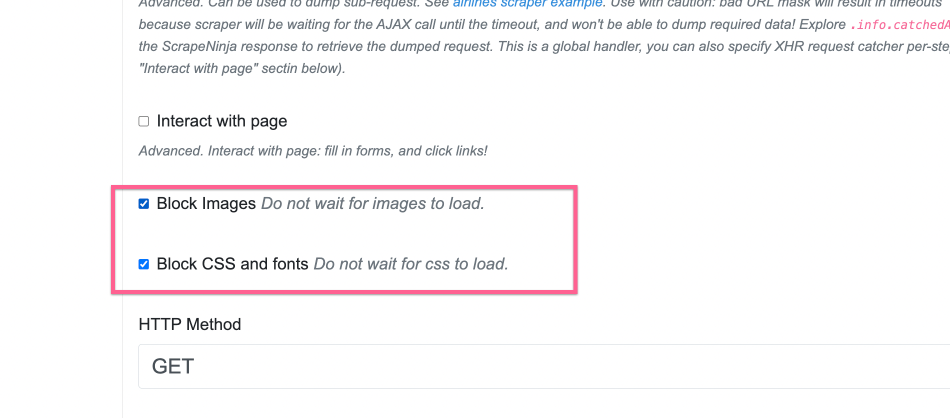
The obvious con of running rendering with "evaluate JS" checkbox is that now request runs slower, and to increase the speed to the rendering, I check "Block Images" and "Block CSS and fonts" settings:
Bypassing captcha by enforcing ScrapeNinja proxy rotation
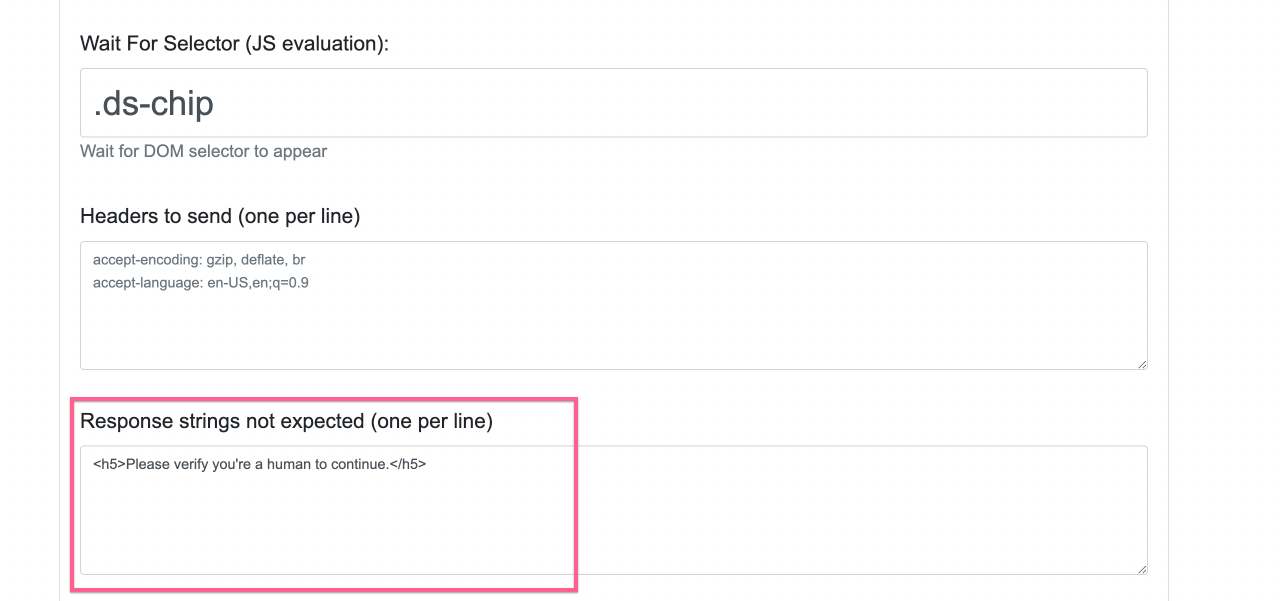
After 10 minutes of experimenting with ScrapeNinja Online Scrapebox, I noticed that I ofter get "verify that you are a human" screen like this:
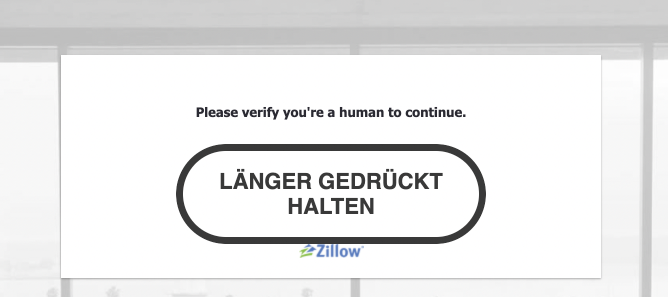
To mitigate this, I'd like to tell ScrapeNinja that "Please verify ..." text means I need to retry the page from another ip address:
Writing JavaScript extractor to get data from HTML
To make web scraper extract useful data from HTML, we finally need to get our hands dirty with JavaScript:
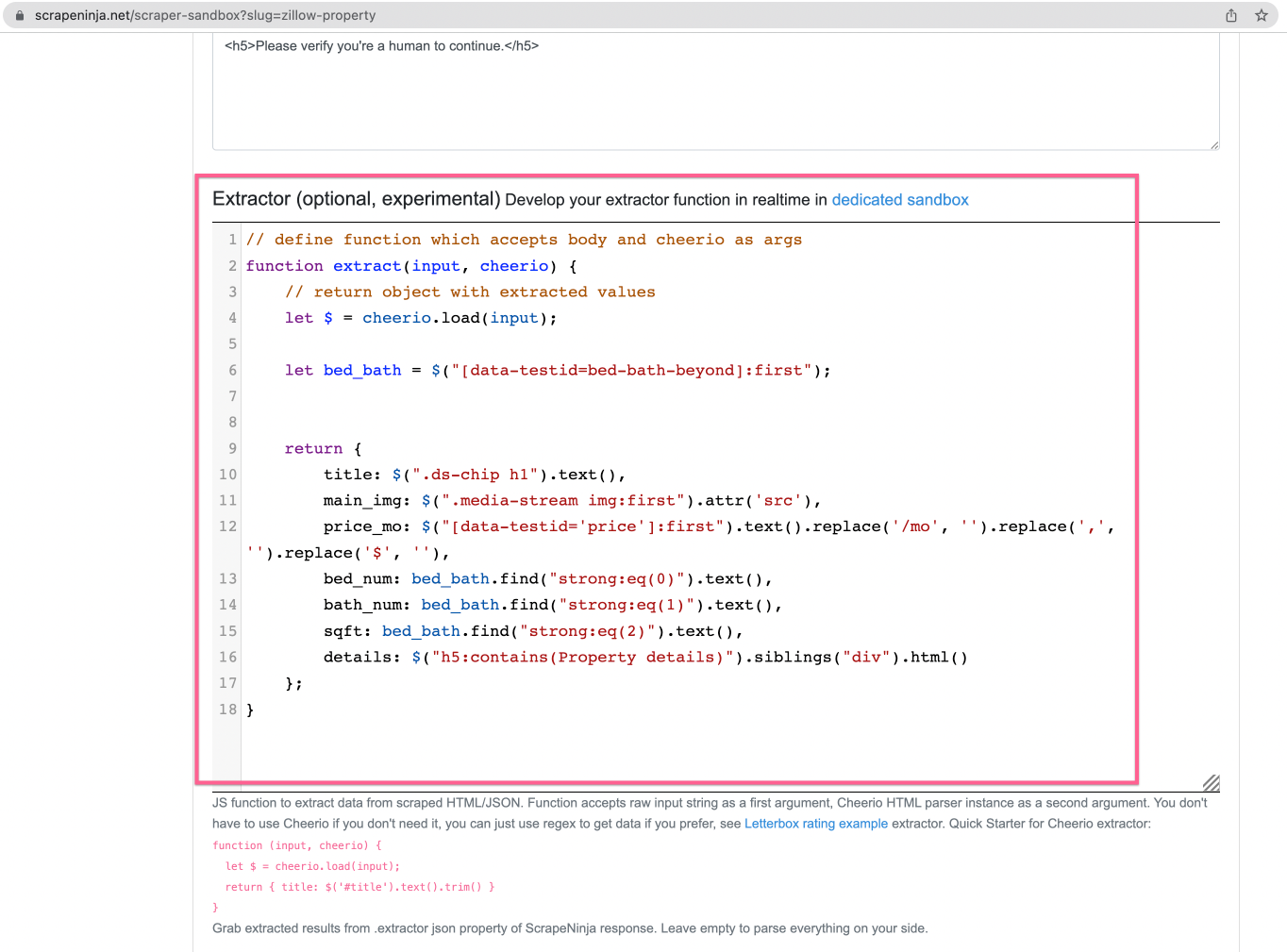
ScrapeNinja uses Cheerio (which is basically jQuery for server-side Javascript), to extract data from HTML so I write 1 function which will contain CSS selectors.
If you are having troubles writing cheerio selectors, check my article about writing Cheerio selectors and using ScrapeNinja playground for this.
The result
Here is the final web scraper:
https://scrapeninja.net/scraper-sandbox?slug=zillow-property
And here is the code that ScrapeNinja generated for me:
import fetch from 'node-fetch';
const url = 'https://scrapeninja.p.rapidapi.com/scrape-js';
const PAYLOAD = {
"url": "https://www.zillow.com/homedetails/1930-S-River-Dr-W805-Portland-OR-97201/2078637838_zpid/",
"method": "GET",
"retryNum": 2,
"geo": "us",
"js": true,
"blockImages": true,
"blockMedia": true,
"steps": [],
"waitForSelector": ".ds-chip",
"textNotExpected": [
"<h5>Please verify you're a human to continue.</h5>"
],
"extractor": "// define function which accepts body and cheerio as args\nfunction extract(input, cheerio) {\n // return object with extracted values \n let $ = cheerio.load(input);\n \n \tlet bed_bath = $(\"[data-testid=bed-bath-beyond]:first\");\n \t\n \t\n return {\n \ttitle: $(\".ds-chip h1\").text(),\n \tmain_img: $(\".media-stream img:first\").attr('src'),\n price_mo: $(\"[data-testid='price']:first\").text().replace('/mo', '').replace(',', '').replace('$', ''),\n \tbed_num: bed_bath.find(\"strong:eq(0)\").text(),\n \tbath_num: bed_bath.find(\"strong:eq(1)\").text(),\n \tsqft: bed_bath.find(\"strong:eq(2)\").text(),\n \tdetails: $(\"h5:contains(Property details)\").siblings(\"div\").html()\n };\n}"
};
const options = {
method: 'POST',
headers: {
'content-type': 'application/json',
// get your key on https://rapidapi.com/restyler/api/scrapeninja
'X-RapidAPI-Key': 'YOUR-KEY',
'X-RapidAPI-Host': 'scrapeninja.p.rapidapi.com'
},
body: JSON.stringify(PAYLOAD)
};
try {
let res = await fetch(url, options);
let resJson = await res.json();
// Basic error handling. Modify if neccessary
if (!resJson.info || ![200, 404].includes(resJson.info.statusCode)) {
throw new Error(JSON.stringify(resJson));
}
console.log('target website response status: ', resJson.info.statusCode);
console.log('target website response body: ', resJson.body);
} catch (e) {
console.error(e);
}Running the scraper on remote server
My Hetzner cloud server uses Ubuntu Linux. I also have node.js v18 on it, already installed – install Node.js if you don't have it yet. And then follow these simple instructions to run the web scraper:
Step 1. Create project folder, initialize empty npm project, and install node-fetch
mkdir your-project-folder && \ cd "$_" && \ npm i -g create-esnext && \ npm init esnext && \ npm i node-fetch -y
Step 2. Copy&paste the code above
Create new empty file like scraper.js and paste the code of the scraper to this file.
Step 3. Launch
node ./scraper.js
Running ScrapeNinja scraper without remote server: Make.com
If you don't have your own server and you don't want to learn how to setup Linux, there is a great alternative way! ScrapeNinja can be run in a no-code environment: ScrapeNinja as an official Make.com integration module. Learn more how Make.com can be used to run no-code web scraper in this Youtube video:
That's it! I have a basic web scraper which can retrieve Zillow property listing, and extract useful information from HTML source of the page. Of course, this is a web scraper built for educational purposes, and there are plenty of things to be done to create a real-world scraper: for example, I would get a list of property items from Zillow page index and the run this page scraper one by one for each listing. Good luck scraping the web!
Read how I scraped Apple.com for refurbished iPhones, with push notifications for alerts.