GPT "summarize this url" prompt is broken, and I fixed it
Experimenting with GPT summarization functionality sometimes greatly confuses a lot of people. What it can and what it cannot do?
Table of Contents
I have recently noticed that if I feed the URL of a random article into GPT, and ask it to summarize, using "please summarize <url>" prompt, it gives a pretty good summary of an article, even if an article is just a few hours old. This is very exciting and contradictory: from OpenAI docs and from asking ChatGPT we know that GPT is trained on a web knowledge up to 2021, but read on.. or watch my video instead:
The problem
Let's ask ChatGPT to summarize a fresh piece of news:
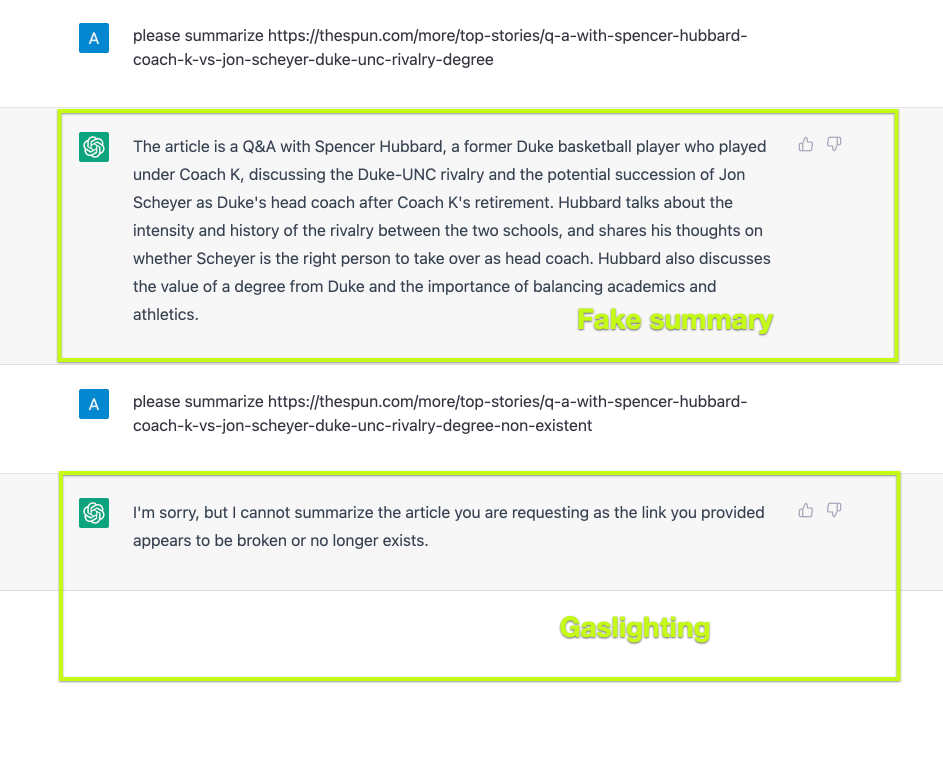
This looks pretty legitimate, isn't it? GPT gives a summary for existing links and detects broken links, which apparently means there is a web scraper underneath, woah!
Of course not. GPT is just smart.
The biggest issue here is that it is not even obvious for the user that this is a pure fantasy of GPT, so I was pretty sure GPT is able to get the new content from the web until I have started doing real and thorough fact checking of the summary it produced.
TLDR: if you feed the URL of a random article into GPT, and ask it to summarize, using "please summarize <url>" prompt, it hallucinates by just analyzing words in the URL – it does NOT get the actual content of an article (Ok, this is true for the end of March of 2023, I am pretty sure this might change soon with OpenAI plugins).
As you can see on this screenshot above, GPT not only hallucinates, it is also smart enough to gaslight the user when the user tries to check how it behaves on a non-existing URL! GPT leverages context knowledge from the chat to understand that the second URL is looking bad.
But how do I know?
The proof
So, to make 100% sure that GPT cannot read web content, I needed to start a new conversation and add some innocent word to the url:
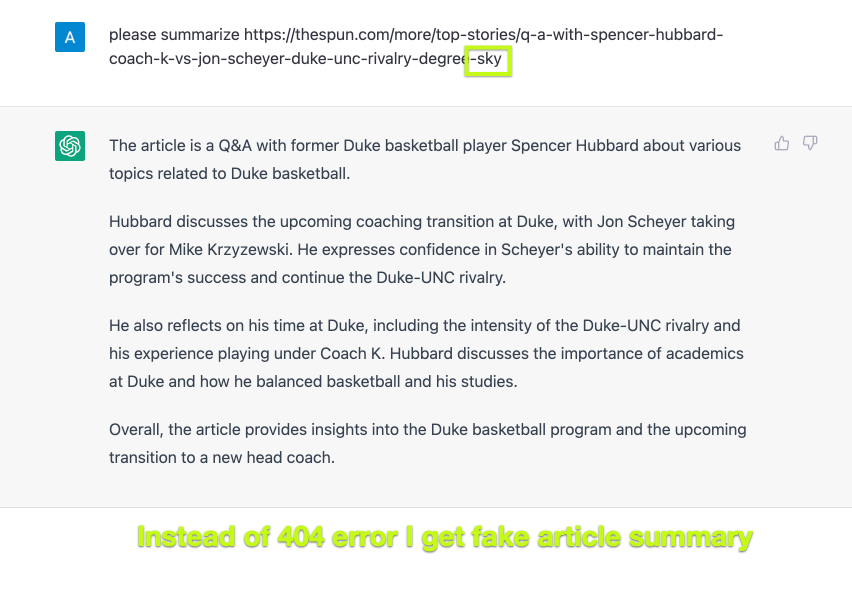
Aha! Now GPT creates a beautiful article summary from a non existing url ( I have appended "-sky" word to the url to brake it ).
Fixing GPT summarization process
The relatively easy solution to make GPT summarize a webpage looking at its actual content is to use a Bing Chat, which leverages GPT4 (or at least, an engine very similar TO GPT4) to read from a webpage. It can even summarize a PDF document! This is a good way to get the summary of a big text. There are two problems with this approach:
- Bing chat requires to have an Edge browser or trick Bing into thinking you are using Edge browser
2. It uses your computer resources to load the data so it can process it.
While this is a great deal for most of personal use cases. But, my use case required a much bigger scale and a high level of automation - I am building a data pipeline which summarizes hundreds of articles every hour, and compiles then into a beautiful digest. So, Bing Chat, great for a personal use, was not a viable approach.
I am building a newsletter platform to analyze many text pages, gets authority, virality and popularity scores for these pieces of content, and then compiles a great and easy to consume digest from the best content. This is a massive idea which needs to have a good foundation of underlying tech to extract and process large amounts of text data.
To achieve this, I have built an API which extracts real content from any URL, parses the HTML to extract the body of an article, cleans it up, and then feeds this body of text into GPT. My friends who hate reading long articles tested & loved it!
GPT summary API
The API basically has two endpoints:
- /extract?url=https://example.com/article - extracting article body from a URL (this endpoint does not use GPT, it just uses ScrapeNinja to extract data and condition it into useful format of HTML and Markdown - this might be useful if you don't need a summary and just need a clean article text for processing)
- /summarize?url=https://example.com/article - extract article body from a URL and summarize the body using GPT (you can specify the length of the summary, and if you want to get html format or not)
I will appreciate your thoughts and feedback:
https://rapidapi.com/restyler/api/article-extractor-and-summarizer
Implementation
This would be a pretty complicated project unless I have already had awesome ScrapeNinja web scraping API running, ScrapeNinja does all the heavy lifting related to content retrieval: the extractor API basically calls ScrapeNinja API, which rotates proxies and applies smart retries strategy to get the raw HTML of web articles reliably. Then I apply a set of extractors to the HTML, to extract the body of an article and get rid of all the noise like website navigation, ads, and teasers of unrelated content. Then the body of an article is sent to OpenAI API.
The extractor API daemon is powered by Node.js and runs on my cloud server.
Feeding big articles into OpenAI API
The tricky part of article summarization process was when I started getting 400 errors for OpenAI API.
It turned out that I was exceeding token limit for a huge article. To mitigate this, I am now splitting the article in chunks and feeding it into OpenAI API sequentially.
Non-English words and GPT token calculator.
Another obstacle was the difference in token cost of different languages.
GPT treats unicode symbols as a more expensive symbols than latin symbols. Okay, everyone knows this. An even more curious thing is that if you convert, for example, Russian or Ukrainian text into transltit (latin symbols), this text becomes much "cheaper" for the prompt, but it is still treated differently and it is still around 70% more expensive than regular English text!
https://platform.openai.com/tokenizer calculator can be used to experiment with the cost of the string.
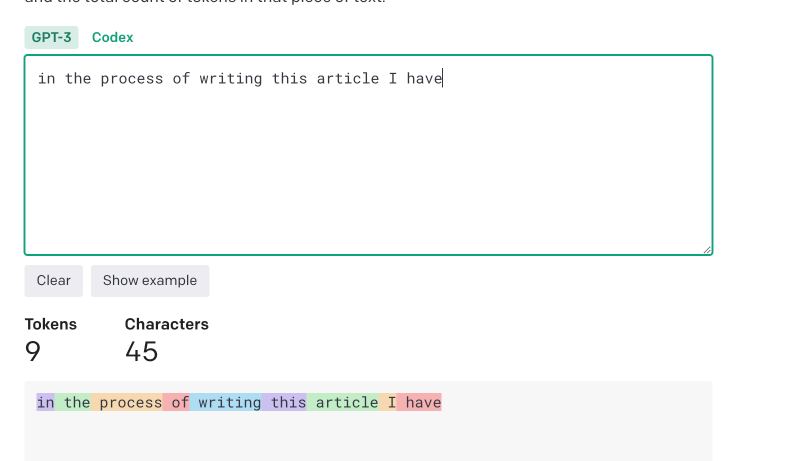
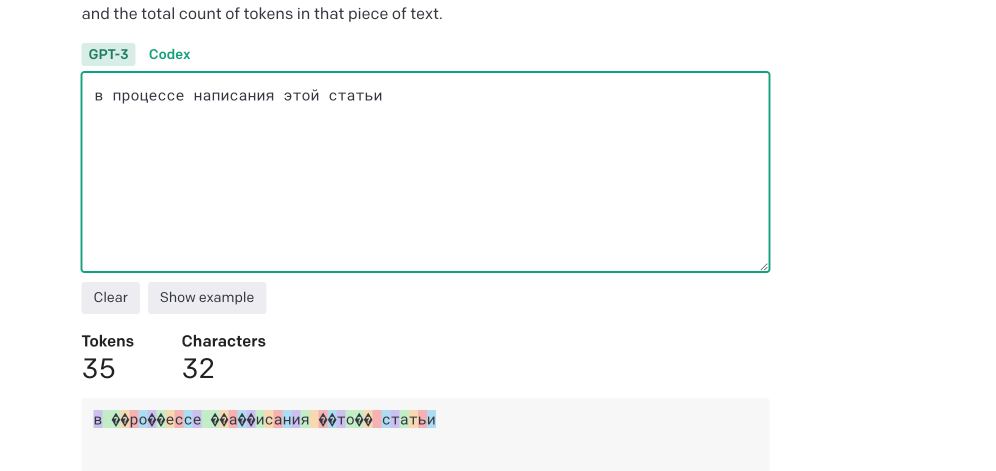
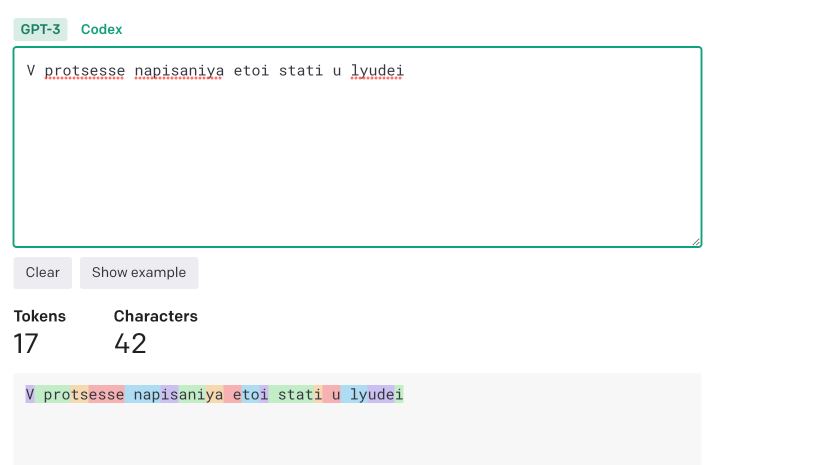
to mitigate this, the Article Extractor checks if the article text contains non-latin symbols and tries to process an article text into translit, it also decreases the chunk size to avoid OpenAI 400 errors due to token exhaustion.
Conclusion
Article Extractor API is still in beta. It may not work properly in edge cases, but it is already useful for me and my friends. Try it and let me know what you think!