Building modern and production ready Node.js API: my boring setup
I know how this desire to try out a new flashy npm package in a quick project can easily paralyze my will and the whole project's progress over exploring new docs and code. So in this writeup I would like to give appreciation to all the tools and techniques that have proven to be effective for me.
Table of Contents
As a founder of ScrapeNinja.net and a big fan of API-first products, I build and deploy a lot of APIs. Since I am a "sprint" guy, I am energized with the quick progress on a project, so over the years I learned to appreciate this momentum when building new APIs from scratch, without spending precious energy on choosing the tech stack.
I love to try out new tools. But, being in the JavaScript ecosystem, I know how this desire to try out a new flashy npm package in a quick project can easily paralyze my will and the whole project's progress over exploring new docs and code. So in this writeup I would like to give appreciation to all the tools and techniques that have proven to be effective for me. TL,DR: This is a neat mix of boring tech (express.js, pm2) and fancy new tech (gpt).
Programming language: Javascript
While Python seems to be more popular across data scientists who are involved in web scraping, these Python projects are usually not a performance critical projects – not trying to say that Python performance is bad, it's just node.js being really fast and a perfect fit to build APIs: event loop, async/await as a first class citizen, and all these huge npm packages like Puppeteer/Playwright being available out of the box. I started my adventure in backend Node.js world from the project where I needed to build a realtime "mirror" of multiple e-commerce websites and modify website design on the fly, on a per-request basis (we were building a custom marketplace of products where we were doing the purchase of goods on behalf of end customers and handling international delivery part on our side). Essentially this was a reverse-proxy with very complex request and response rewriting rules. This project was a huge challenge for me as back in the days I was a PHP guy who had no idea how node.js worked in real production and this was a paradigm shift (btw I used node-http-proxy package back then). It was 2017, I think, and I am building real-time web scraping APIs and API gateways which log and monetize APIs since then, still enjoying Node.js with all its quirks, pains and advantages.
Runtime environment: Node.js
Node.js is a mainstream environment for running JS on backend.
I use v16 and v18 of Node.
NPM packages I use for every Javascript API in 2023
Here is how I start my node.js API project:
npm init -y
npm i express dotenv express-async-handler mochaThen I edit package.json and add "type": "module", to it so I can use "import" instead of "require" which was a CommonJS standard. Here is an example package.json which I have as a starter:
{
"name": "starter",
"version": "1.0.0",
"description": "",
"type": "module",
"main": "index.js",
"scripts": {
"dev": "PORT=4005 node src/server.js",
"test": "mocha --recursive 'tests/**/*.js' --timeout 15000"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"dotenv": "^16.0.3",
"express": "^4.18.2",
"express-async-handler": "^1.2.0",
"mocha": "^10.2.0"
}
}
Express.js and async/await via express-async-handler
While Express.js is not exactly modern, it's still a perfectly viable solution to build an API in 2023. It's fast, simple, and gets the job done. I can safely say it is now a boring tech (which is a good thing). To make it work properly with async/await, I use express-async-handler package, and here is how my /src/server.js looks like:
import dotenv from 'dotenv';
dotenv.config();
import express from 'express';
import asyncHandler from 'express-async-handler';
import validUrl from 'valid-url';
import { method1, method2, method3 } from '../src/lib.js';
const app = express();
app.get('/process', asyncHandler(async (req, res) => {
const url = req.query.url;
let json = await method1(url);
res.json(json);
}));
// Define a custom error handling middleware
app.use((err, req, res, next) => {
console.error(err); // Log the error for debugging purposes
// Render a more descriptive error message as a JSON response
res.status(503).json({ error: `An error occurred: ${err.message}` });
});
app.listen(process.env.PORT, () => {
console.log(`Server started on port ${process.env.PORT}`);
});
the asyncHandler wrapper around every callback of Express.js endpoint is needed so if method1() throws an exception, it is properly handled using generic error exception handler. It basically allows to avoid writing top-level try { } catch {} blocks in every endpoint. And, if you don't write these try-catch blocks, and do not use asyncHandler package, any unhandled exception will hang the specific request which caused the exception, indefinitely.
Another alternative would be to use koa.js or fastify frameworks which are handling async-await callbacks properly out of the box, but I just stick to Express.js because it is not a big enough reason for me to switch over.
dotenv
The dotenv npm package is a popular tool used in Node.js development to manage environment variables. It allows me to store sensitive configuration data, such as API keys or database passwords, outside of my codebase and instead load them into the application at runtime. This makes it easier to keep sensitive information secure and separate from the rest of the code. With dotenv, I create a .env file containing key-value pairs of my environment variables and then use the process.env object to access those values in my code.
Thing to note is that if you import method1 which is located in /src/lib.js file BEFORE you imported and initialized dotenv, the code inside the method1 won't be able to read process.env.VAR variable which was defined in .env file, so make sure you do dotenv launch before any imports if your imports rely on some process.env vars from .env file.
Running API calls: Postman alternative
To test how my API behaves, I am using awesome VS Code REST.client extension which is a wonderful alternative to using Postman and cURL.
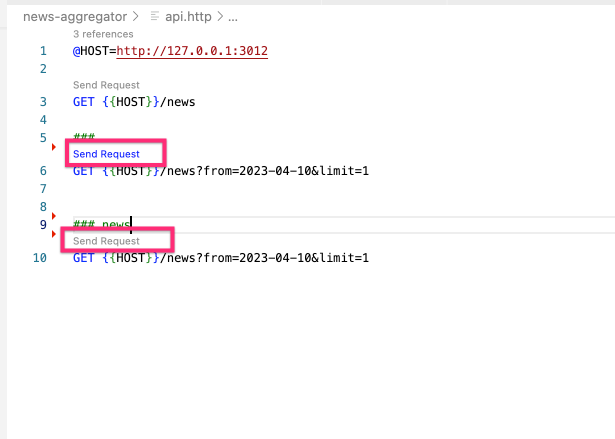
For me, Postman/Paw/https://hoppscotch.io/ UI just feels too feature rich, overloaded and bloated, and I just prefer lean CLI and minimalistic text interfaces when it is possible, but at the same time cURL is way too low level (though I still use cURL a lot). There is something magical in the simplicity of having a human readable file with sample API calls, committed into Github repo along with my API code. The thing I like about this extension is that it is a plain text file with .http extension in my project root, and it looks like this:
@HOST=http://127.0.0.1:3012
GET {{HOST}}/news
###
GET {{HOST}}/news?from=2023-04-10&limit=1
### news
GET {{HOST}}/news?from=2023-04-10&limit=1REST.client augments such file with runnable controls:
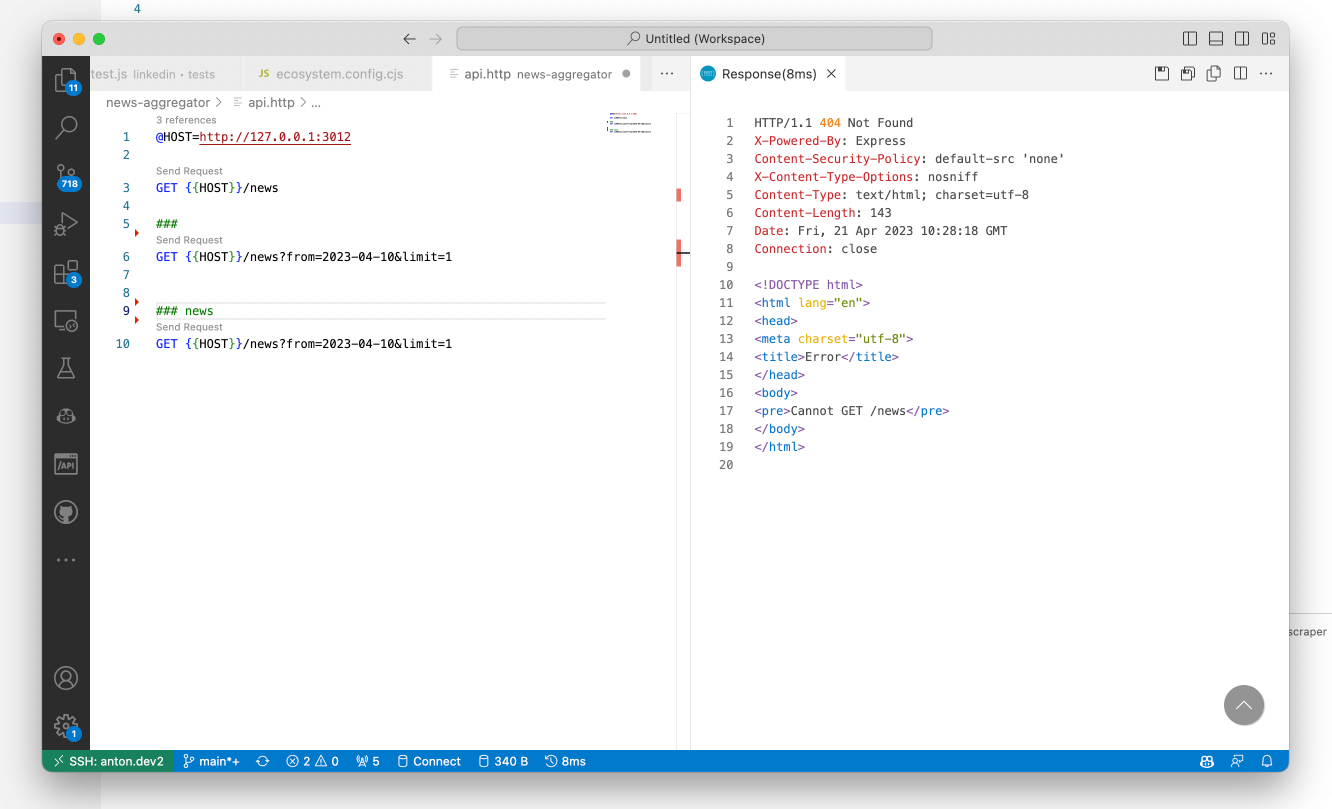
And the best part of REST.client is that all my API management is sitting in good old and fast VS Code as a regular file, so I need to spend milliseconds to click "send request" link and get the response, without spending precious seconds of switching to another app:
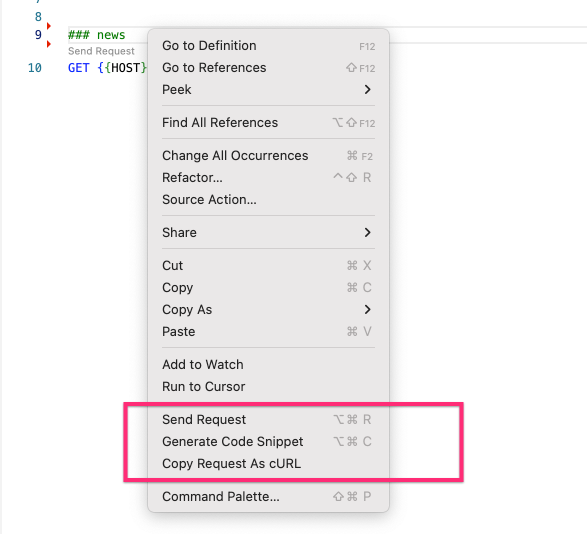
Right click allows to quickly generate cURL command for a particular API call if I want to do a raw cURL request from my terminal:
Running the process: PM2
I have tried all the popular solutions for running node.js daemons: systemd, supervisorctl, docker, pm2.
PM2 is my current preference for basic Node.js APIs - it's simple, very logical so I don't need to google its launch syntax, and it allows two ways of running Node.js process: pm2 start /src/server.js --name processname and ecosystem files.
I prefer the ecosystem file lately, especially if my Node.js app contains two or three servers (e.g. express.js server and some cron-like or queue-like scheduler). This pm2 service file sits in the root of Node.js project: ecosystem.config.cjs and looks like this:
module.exports = {
apps: [
{
name: 'news-agg-server',
script: './src/server.js'
},
{
name: 'news-agg-scheduler',
script: './src/scheduler.js'
}
]
};
Notice that it has .cjs file extension as the syntax used by PM2 here is CommonJS standard, not ES6 exports standard.
So if I want to restart the project production process, I don't need to remember what is the name of the daemon process, I just get into project folder and launch pm2 restart ecosystem.config.cjs and this is a huge relief.
Generating OpenAPI spec: GPT
For my internal projects, I am lazy and I usually do not generate OpenAPI spec, my server.js is a source of truth. But if my API is being built for someone else to consume, it was always a pain for me to use UIs for OpenAPI or to load the syntax of OpenAPI Yaml back into my memory, and now I mitigate this with great success using GPT – and the best part is that I don't need to leave the comfort of my VS code to do it, as I use Genie GPT extension:
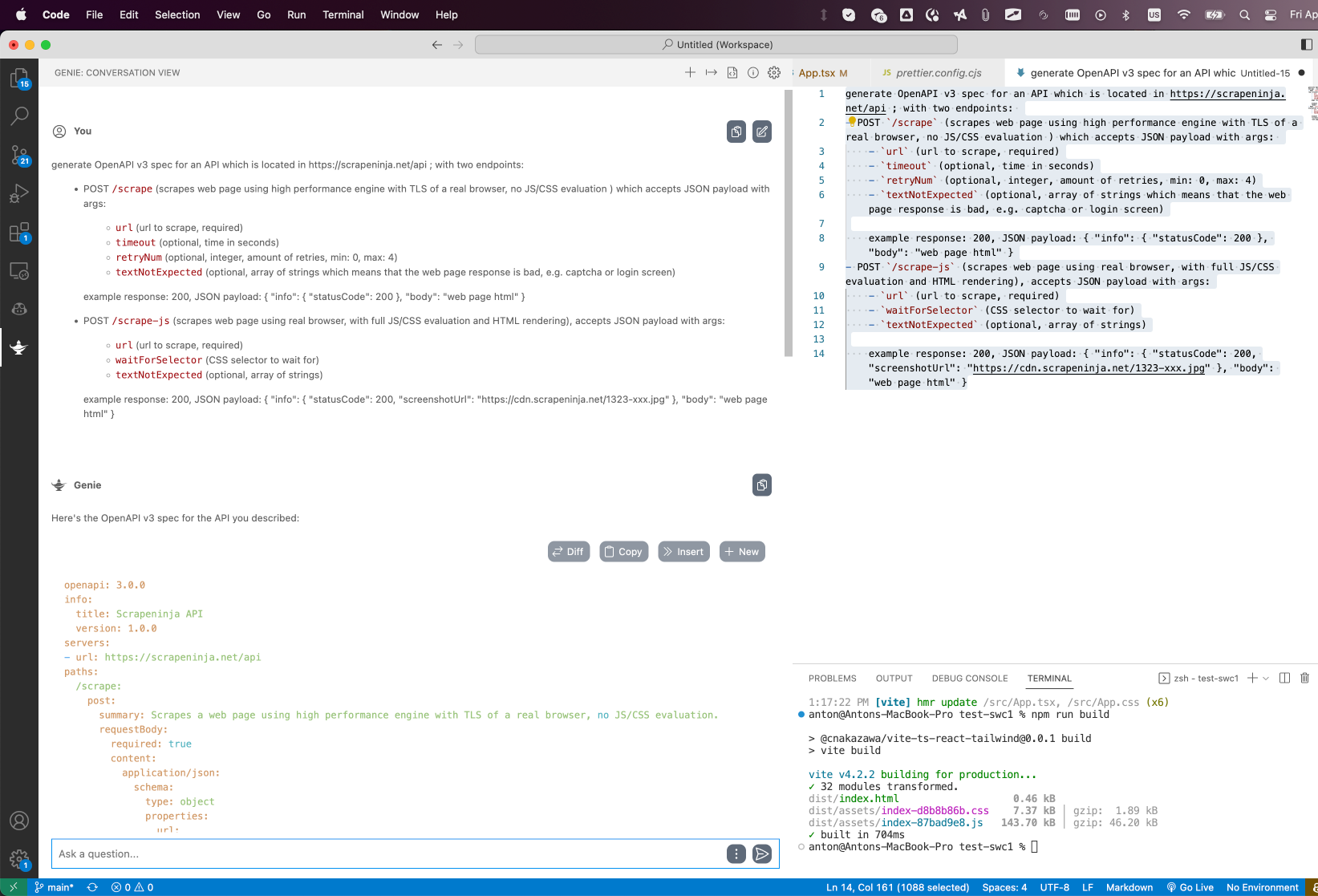
Writing tests for Javascript: Mocha & GPT
I am using Mocha library and I am trying to use GPT to generate tests - this approach is not perfect (and major pain here is 4000 max tokens limit), but for smaller functions it usually produces good enough results so I don't need to type this boring boilerplate again and again:
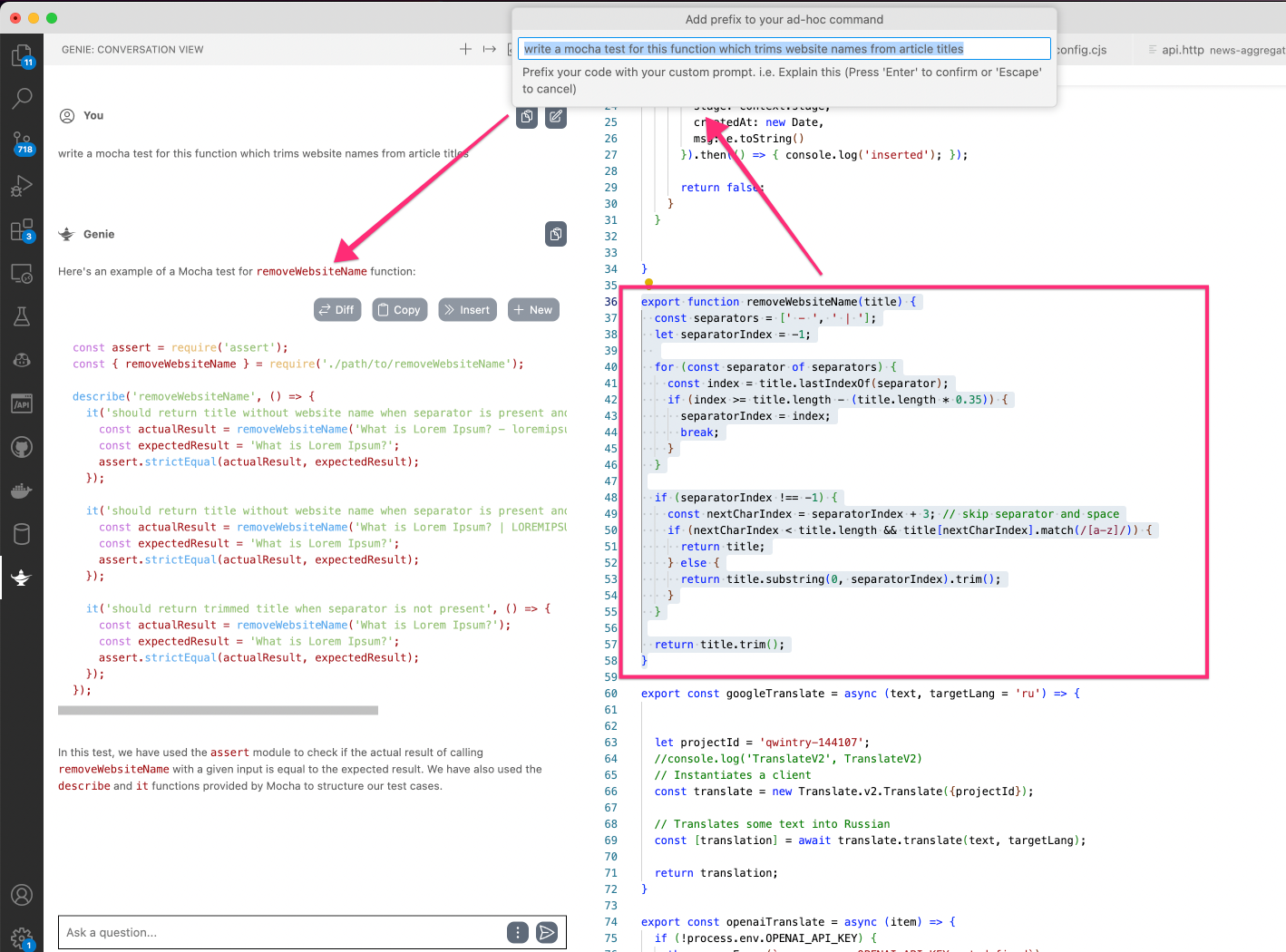
Mocha is smart enough to process async/await test methods, which is great.
Writing Dockerfiles and docker-compose: GPT
If my project has some complex requirements, e.g. it needs to have Puppeteer or certain Node.js version, I wrap it into Dockerfile and docker-compose.
Databases: mysql & knex.js
As my APIs tend to be small or medium size, after spending some time and resources using Objection.js and Sequelize, I got rid of ORM/Active Record patterns completely, and I am now always using very barebones setup: knex is my perfect companion which allows to insert rows from JSON objects, and do selects using good & old raw SQL, against MySQL, with great performance, and I don't need to spend time and energy describing my tables structure in another DSL language like I was doing it in Objection.js.
I will be honest with you - I also tried to get rid of MySQL and just use pure JSON files to dump application state to a disk, so it could be restored on node.js server restart, but this was not working reliably enough and sometimes JSON files got corrupted. I am going to try using SQLite some day for this purpose but for now I just stick to MySQL because it gets the job done and this is what I know best.
Why not MongoDB? I doubt it can be web-scale.. ok just kidding. Though I like the idea of dumping JSON structures into DB and JS as a first-class citizen for traversing objects inside DB, I am an SQL guy and I also had a bad experience using MongoDB in one of our projects.
If I need to store huge time series data, like in apiroad.net, I use Clickhouse, which is a great example of a modern software which is convenient to use in a one-man project, but can scale to 100-men project, without being a huge pain in *ss.
Muscle memory and habits are the key
As I have already said, sticking to the same patterns provides a great relief: I have 30+ small API projects in my Github account, and most of them use the same structure:
/src
/server.js
/lib.js
.env
ecosystem.cjs
api.http
openapi.yaml
package.json
README.mdI always know that npm run dev will launch a dev server and I can test it out by opening api.http .