Web scraping in n8n
Table of Contents
I am a big fan of n8n and I am using it for a lot of my projects. I love that it provides a self-hosted version and this self-hosted version is not paywalled like if often happens with so-called "open core" products which just use "open source" as a marketing term.
Web scraping in n8n can be both simple and sophisticated, depending on your approach and tools.
In this blog post, I will explore two ways of scraping: basic HTTP requests and advanced scraping techniques using ScrapeNinja n8n integration. Whether you're building a price monitoring system or gathering competitive intelligence, this guide will help you choose the right approach.
n8n is a powerful low-code automation platform that allows building complex workflows without writing code. While it's similar to Zapier and Make.com, it offers more technical flexibility and can be self-hosted, making it perfect for data-intensive operations like web scraping.
Compared to custom-built web scrapers where you can often find yourself digging through cryptic text logs, n8n provides a very nice observabiliy out of the box: "Executions" tab on each scenario allows to explore how everything goes and where/how errors, if any, happen. This applies not just to web scraping scenarios, but any scenario in n8n, of course, but if you ever scraped some real website you know how often web scrapers break and require maintenance - this indeed can be painful!
ScrapeNinja is a web scraping API built to mitigate common challenges in modern web scraping. It provides high-performance scraping capabilities with features like real browser TLS fingerprint emulation, proxy rotation, and JavaScript rendering. All this complexity is packed into two simple API endpoints: /scrape?url=<target_website> and /scrape-js?url=<target_website - there are plenty of params to control the behaviour of ScrapeNinja but n8n node simplifies our life because most of these API params have UI controls and it's rather easy to find out how it works.
The integration between n8n and ScrapeNinja combines the power of workflow automation with enterprise-grade scraping capabilities.
HTTP Node
Understanding the Basics
The HTTP node is your gateway to web scraping (and HTTP requests in general) in n8n. It's the Swiss Army knife of HTTP requests, capable of GET, POST, PUT, and other methods. While it might seem straightforward, there's more than meets the eye when it comes to its configuration and retry capabilities.
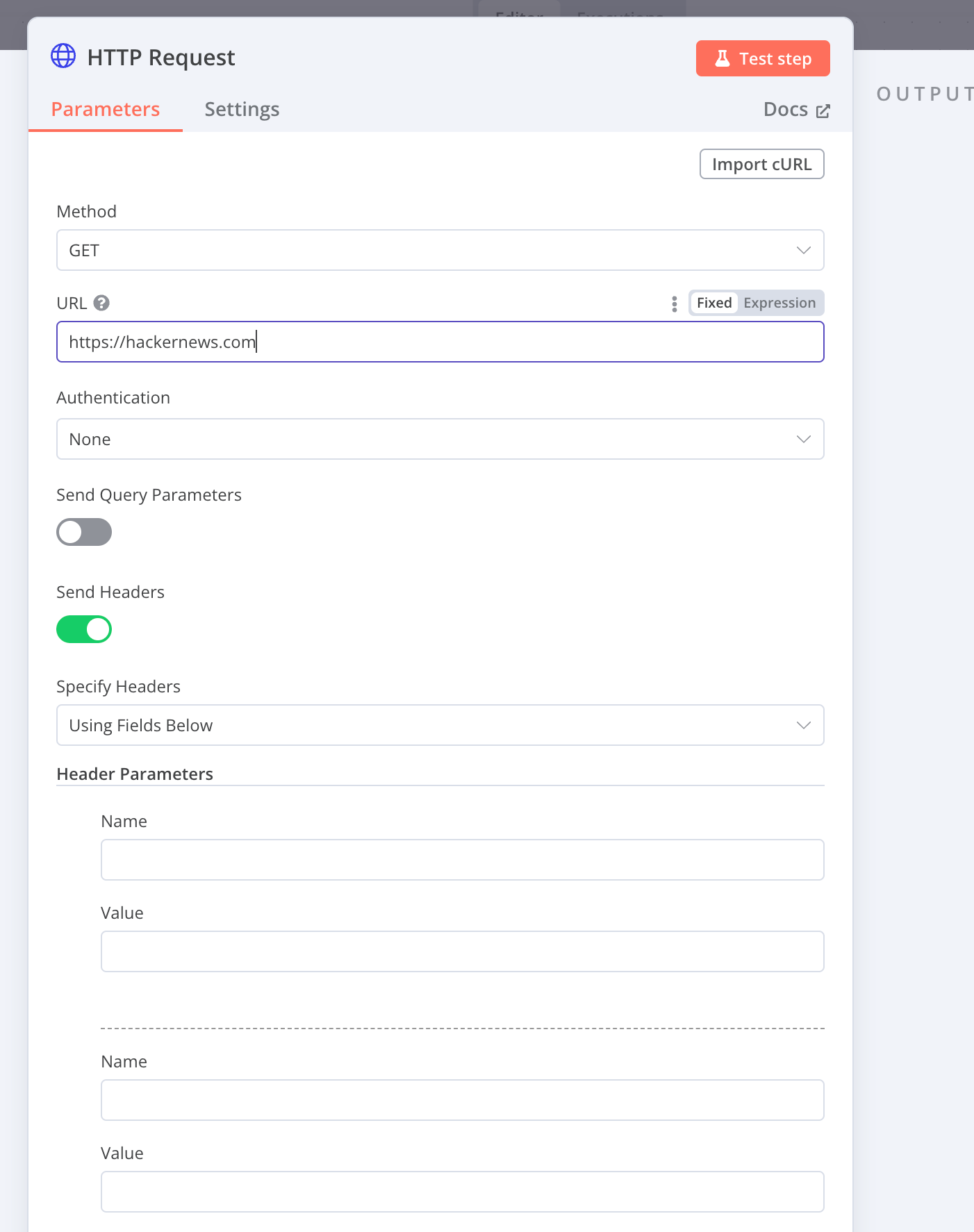
Request Handling
Once you start using the HTTP node for real-world web scraping, you quickly realize it's a pretty nice tool with a lot of available settings.
It works fine if you're scraping your own 10-page website. But if you try scraping another website, you'll likely run into some obstacles:
- Default settings don’t make much sense. The n8n HTTP node’s default user agent is
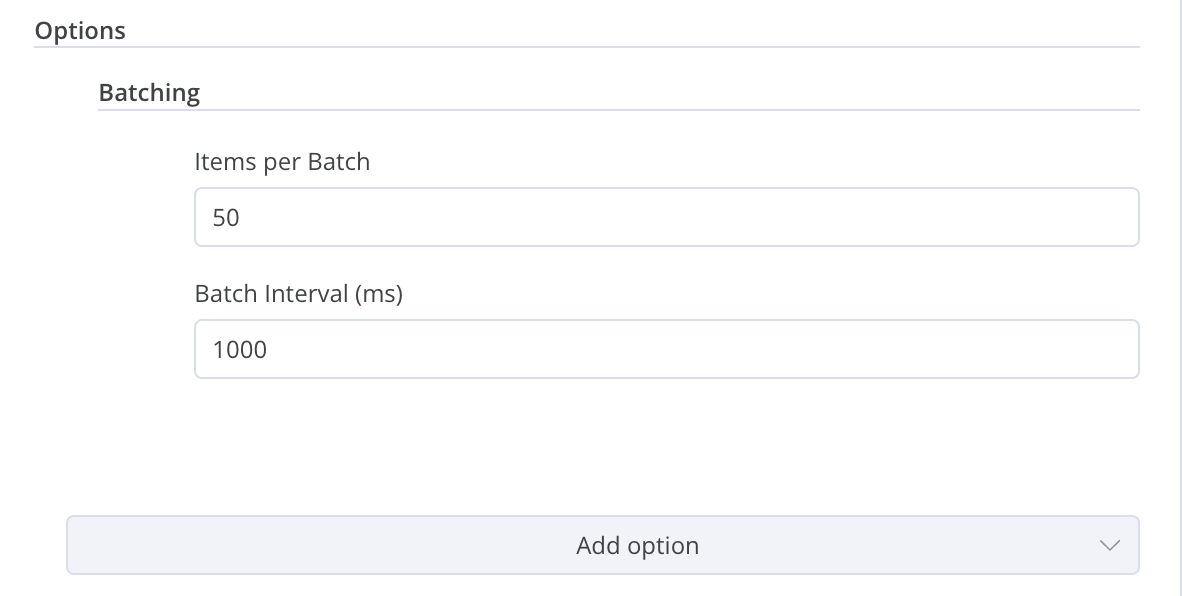
axios/xx. I recommend setting it to something more realistic, like the latest Chrome version (copy it from Chrome Dev Tools -> "Copy as cURL" or visit this website and copy it from there). - HTTP node is concurrent by default. Unless you enable the "Batching" option, the HTTP node will send all your requests simultaneously. Not very intuitive—and a quick way to get your IP banned!
- No TLS fingerprinting bypass. All requests are made via the Axios npm package, meaning they share the default Node.js TLS fingerprint. If the target website uses Cloudflare bot protection, it will detect that your request isn’t from a real browser (even with a proper user agent) and return a 403 — no matter what IP you're using!
- No proxy rotation. The HTTP node doesn't support proxy rotation. Not surprising, since it’s a relatively advanced feature found in dedicated web scraping tools, and the HTTP node was never designed for that purpose.
Response Handling
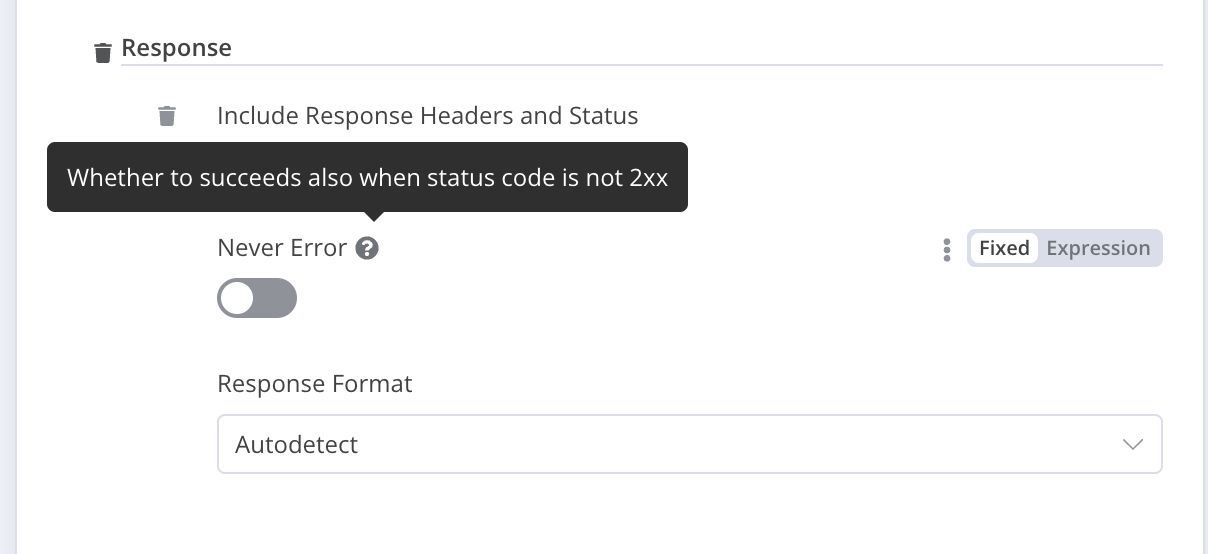
The HTTP node provides several important response configuration options:
- Response Format: Automatically detects and parses various formats (JSON, XML, etc.)
- Response Headers: Option to include response headers in the output
- Response Status: Can be configured to succeed even when status code is not 2xx
- Never Error: When enabled, the node never errors regardless of the HTTP status code
Retry Mechanics
The HTTP node comes with built-in retry functionality that can be a lifesaver when dealing with unstable connections or rate-limited APIs. Like all n8n nodes, it includes a generic retry mechanism for handling failures. However, this basic retry system is often too simplistic for real-world web scraping, where you need granular control over retry conditions based on specific response content or status codes.
Here's what you need to know about HTTP node retries:
- Retry Options: You can set both the number of retries and the wait time between attempts
- Generic Nature: The retry mechanism is designed for general HTTP failures, not specialized scraping scenarios
However, these retries are "dumb" - they use the same IP address and request fingerprint, which often isn't enough for serious scraping operations.
Notable Feature: cURL Command Import
One of the most useful features is the ability to import cURL commands directly. This makes it incredibly easy to replicate browser requests - just copy the cURL command from your browser's developer tools and paste it into n8n. I have encountered some failures of cURL import feature, due to outdated npm library which is used by n8n to parse cURL syntax under the hood, but it was happening on a relatively complex requests copy&pasted from Chrome Dev Tools console, chances that you will enounter these is pretty low, at least on simpler requests.
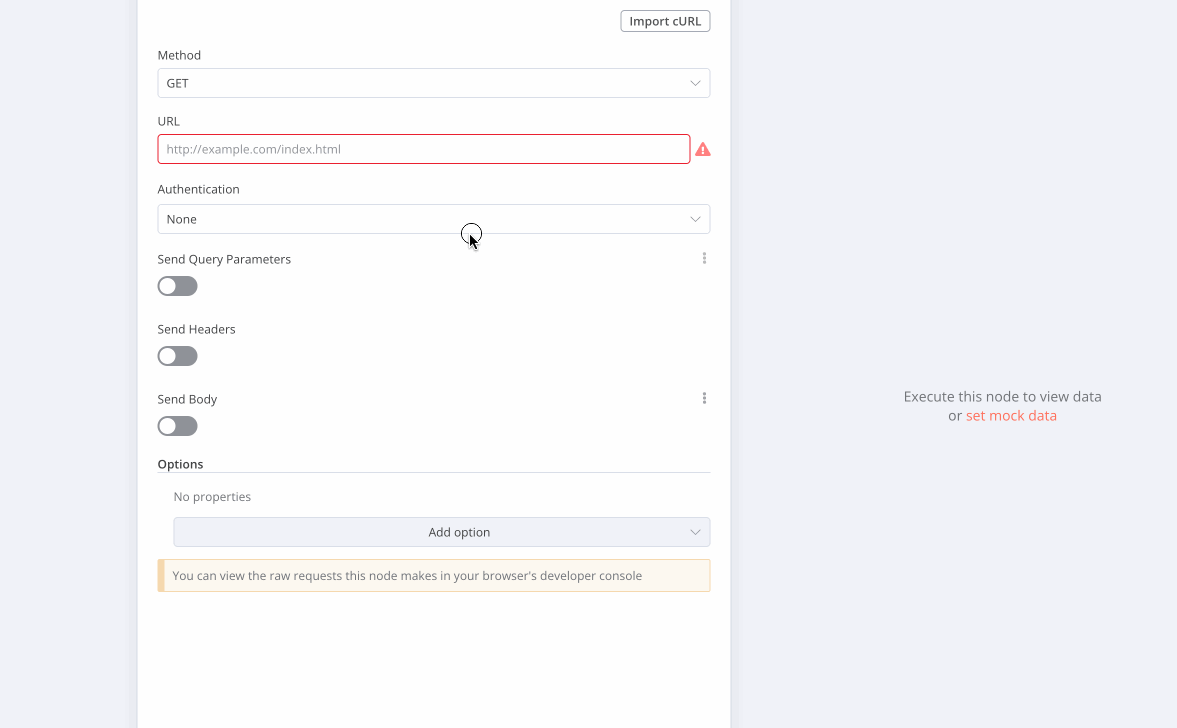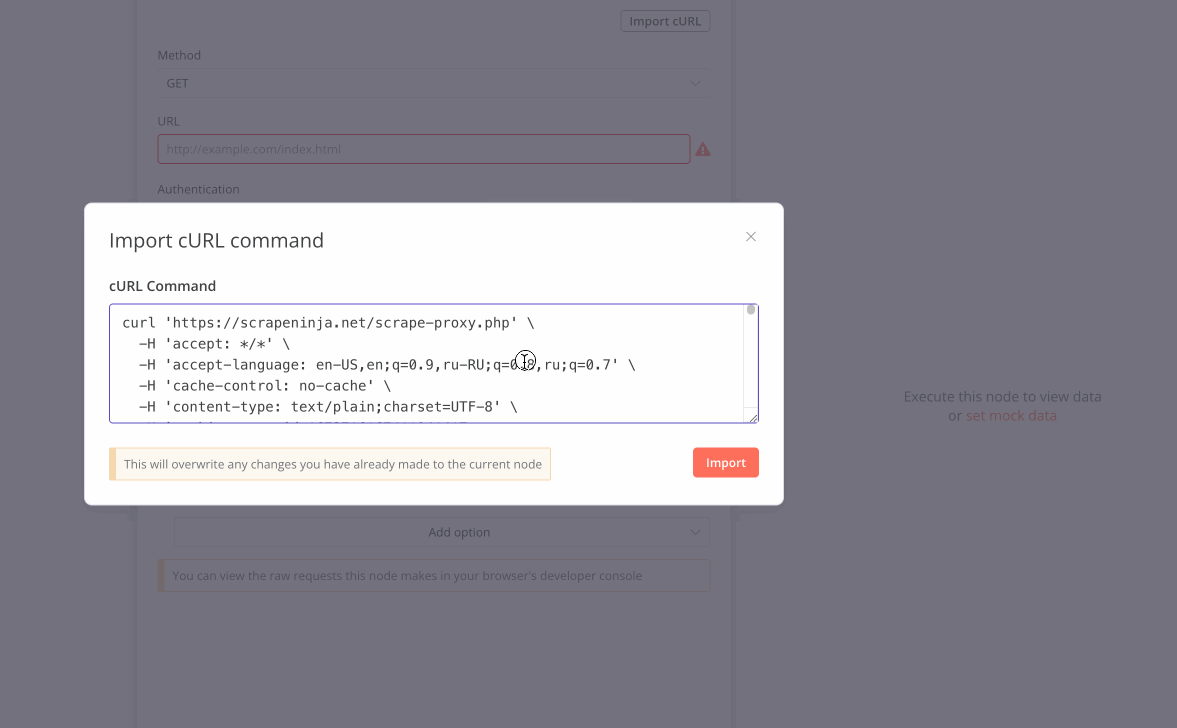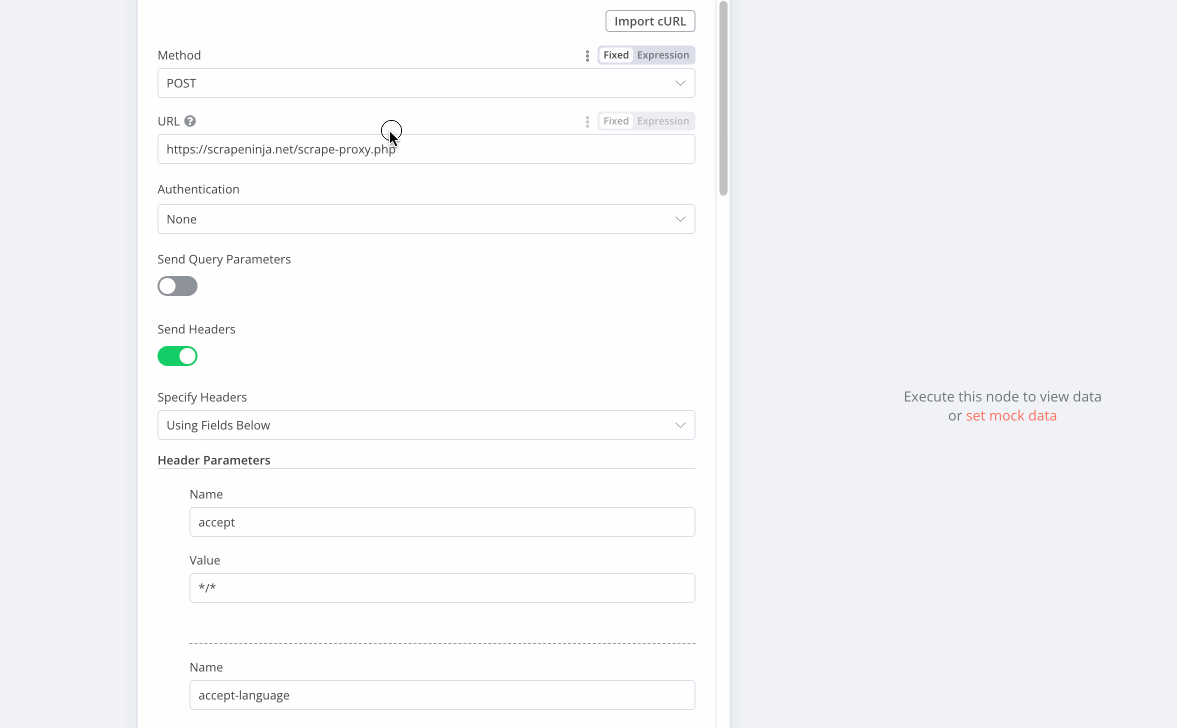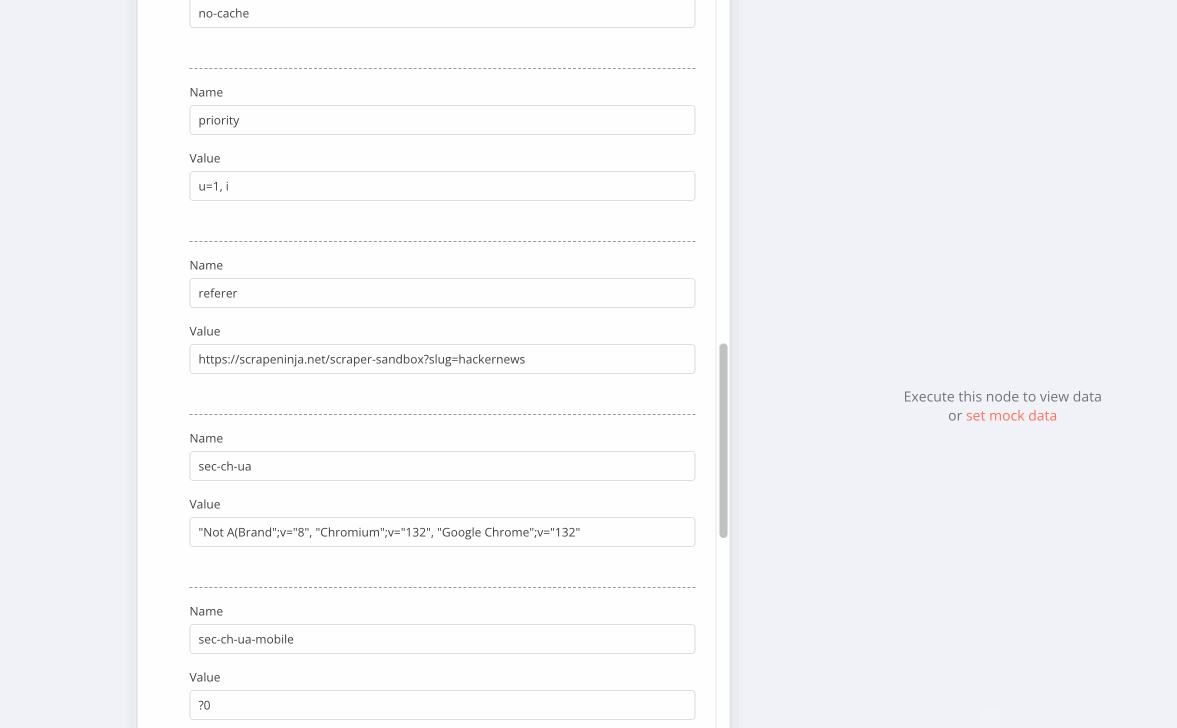
Proxy Support Challenges
While the HTTP node does support proxies, there are known issues with proxies. As mentioned in the n8n community forum and this Github issue, you might get troubles with proper proxy support because underlying npm library which n8n uses for HTTP node (Axios) does not support proxies which require https connection via CONNECT method properly.
ScrapeNinja Node
How It Works
The ScrapeNinja n8n community node is a set of tools designed for web scraping and content extraction.
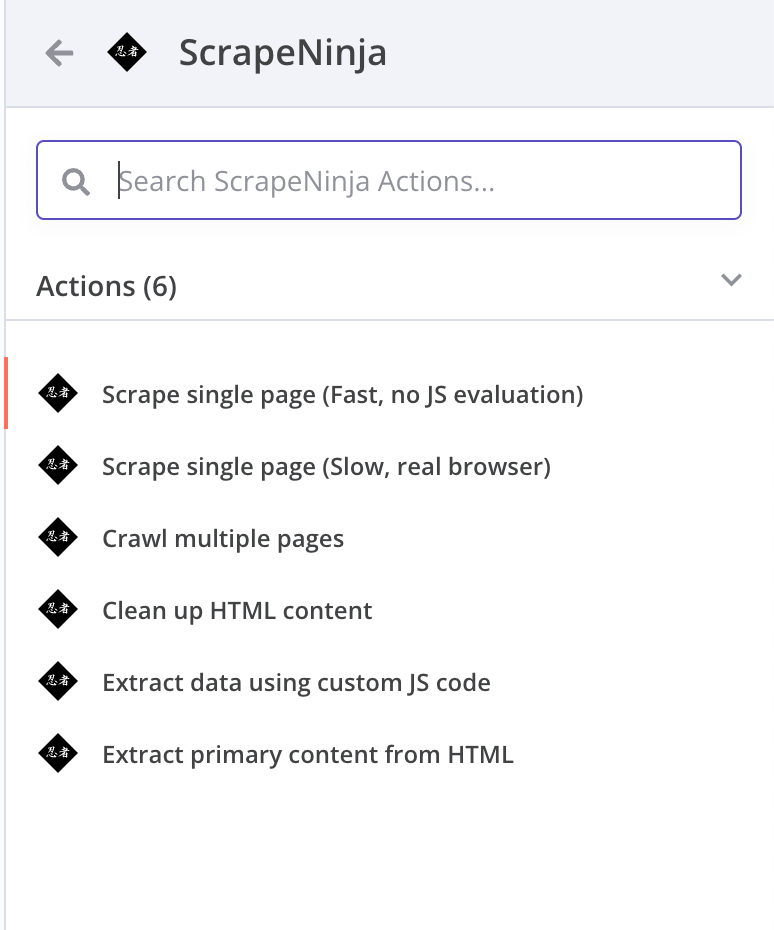
Some operations retrieve content from target websites, while others simplify content extraction from website responses.
Read more in the ScrapeNinja docs.
Request Flow
For content retrieval, the request flow works as follows:
[your n8n self-hosted instance] → [HTTP Node Helper] → [ScrapeNinja API] → [Target Website]
The ScrapeNinja API includes two powerful scraping engines designed to work reliably while bypassing various anti-scraping protections. All of the requests to target websites are completed via rotating proxies.
The Power of Advanced Scraping
ScrapeNinja transforms n8n from a basic scraping tool into a serious web harvesting platform. It's not just another HTTP client - it's a specialized scraping service that handles the complex challenges of modern web scraping. As a SaaS solution, it requires an API key and offers both free and paid plans to suit different scraping needs.
Core Capabilities
The official ScrapeNinja node for n8n brings several nice capabilities:
- Chrome-like TLS fingerprinting
- Automatic proxy rotation with multiple countries of proxies
- JavaScript rendering
- Built-in HTML parsing (JS Extractors)
- Cloudflare bypass capabilities
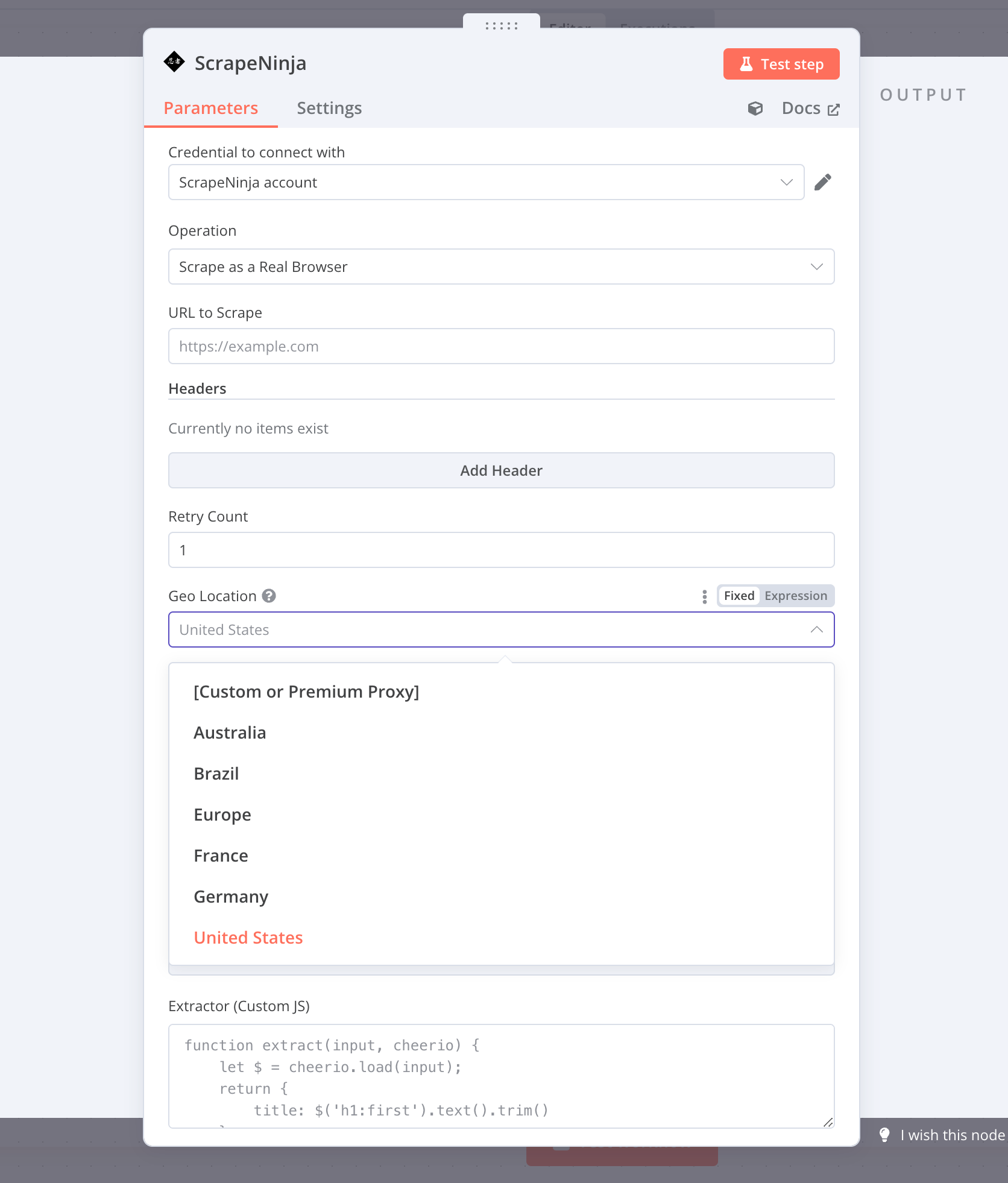
- Built-in, locally executed crawler, which traverses through website links and retrieves all pages content recursively
Response Structure
ScrapeNinja always returns a consistent JSON structure, making it easy to process responses in your workflows:
{
"info": {
"version": "2",
"statusCode": 200,
"statusMessage": "",
"headers": {
"server": "nginx",
"date": "Sat, 25 Jan 2025 16:20:22 GMT",
"content-type": "text/html; charset=utf-8",
// ... other headers
},
"screenshot": "https://scrapeninja.net/screenshots/abc123.png" // when screenshot option is enabled
},
"body": "<html>... scraped content ...</html>",
"extractor": { // when JS extractor is provided
"result": {
"items": [
[
"some title",
"https://some-url",
"pr337h4m",
24,
"2025-01-25T14:47:33",
// ... extracted data
],
// ... more items
]
}
}
}
This structured response provides:
- Complete request metadata in the
infoobject - Original response headers
- HTTP status information
- Screenshot URL (when enabled)
- Raw response body
- Structured data from JS extractors (when JS extractor code is provided in request)
JavaScript Extractors
One of ScrapeNinja's most powerful features is its JavaScript extractor functionality. These are small JavaScript functions that run in the ScrapeNinja cloud to process and extract structured data from scraped content. Here's what makes them special:
- Cloud Processing: Extractors run in ScrapeNinja's cloud environment, reducing load on your n8n instance
- Cheerio Integration: Built-in access to the Cheerio HTML parser for efficient DOM manipulation
- Clean JSON Output: Perfect for no-code environments where structured data is essential
- Reusable Logic: Write once, use across multiple similar pages. Also both ScrapeNinja
/scrapeand/scrape-jsengines are using the same extractors, so switching to real browser rendering later when you suddenly decide to do it, is easy.
AI-Powered Extractor Generation
ScrapeNinja provides a cool Cheerio Sandbox with AI capabilities that helps you create extractors:
- Automated Code Generation: Paste your HTML and describe what you want to extract
- Interactive Testing: Test your extractors in real-time against sample data
- AI-Assisted Improvements: Get suggestions for improving your extractors
- Optimization Features: The system automatically handles HTML cleanup and compression
Feature Comparison: HTTP Node vs ScrapeNinja Node
Here's a detailed comparison of features between the two nodes:
| Feature | HTTP Node | ScrapeNinja Node |
|---|---|---|
| Availability | Built-in n8n node | Requires API key (free/paid plans) |
| Basic HTTP Methods (GET, POST, etc.) | ✅ | ✅ |
| Custom Headers | ✅ | ✅ |
| Query Parameters | ✅ | ✅ |
| Follow Redirects | ✅ | ✅ |
| cURL Import | ✅ | ❌ |
| JavaScript Rendering | ❌ | ✅ |
| Screenshot Capture | ❌ | ✅ |
| Built-in Proxy Support | Limited | ✅ |
| Smart Retries (by content) | ❌ | ✅ |
| Retry on Unexpected Text | ❌ | ✅ |
| Retry on Unexpected Status | ❌ | ✅ |
| Automatic Proxy Rotation | ❌ | ✅ |
| Cloudflare Bypass | ❌ | ✅ |
| Browser Fingerprinting | ❌ | ✅ |
| HTML Parsing | ❌ | ✅ |
| Response Validation | Basic | Advanced |
| Geolocation Targeting | ❌ | ✅ |
Setting Up ScrapeNinja in n8n
Getting started with ScrapeNinja in n8n is straightforward:
- Install the community node (
n8n-nodes-scrapeninja) - Configure your API credentials (supports both RapidAPI and APIRoad)
- Start using advanced scraping features
Read more on n8n community forum
Real-World Scraping Scenarios
Let's look at some common scenarios where n8n can be used for web scraping:
AI agent that can scrape webpages
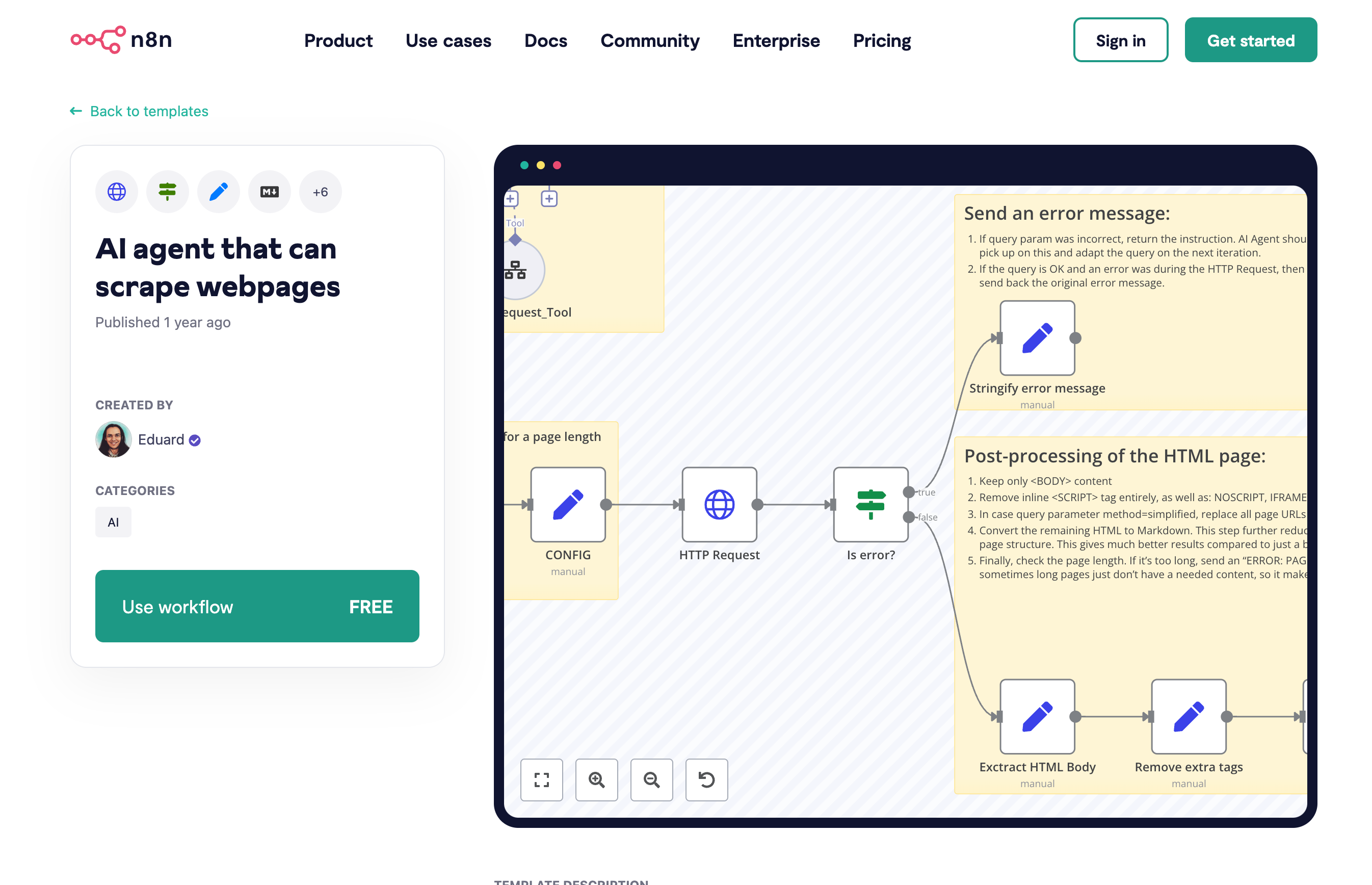
This is an example of real-world workflow where Scrapeninja is probably a better fit compared to HTTP node.
https://n8n.io/workflows/2006-ai-agent-that-can-scrape-webpages/
If you want to get better in n8n, it is useful to check how workflow author is using n8n tools to cleanup HTML so it can be ingested into LLM context, and n8n workflow execute node to split scenario into smaller isolated parts. The HTML cleanup looks rather simplistic and I think using some external API like Article Extractor and Summarizer /extract endpoint may be more bulletproof.
E-commerce Data Collection
When scraping e-commerce sites, you often need to:
- Handle JavaScript-rendered content
- Navigate through pagination
- Extract structured data from complex layouts
- Bypass anti-bot measures
ScrapeNinja handles all these challenges while maintaining a high success rate.
Social Media Monitoring
Social platforms are notoriously difficult to scrape due to:
- Sophisticated bot detection
- Dynamic content loading
- Rate limiting
- Complex authentication requirements
The ScrapeNinja node's advanced fingerprinting and proxy rotation make these challenges manageable.
n8n caveat: HTTP request concurrency control
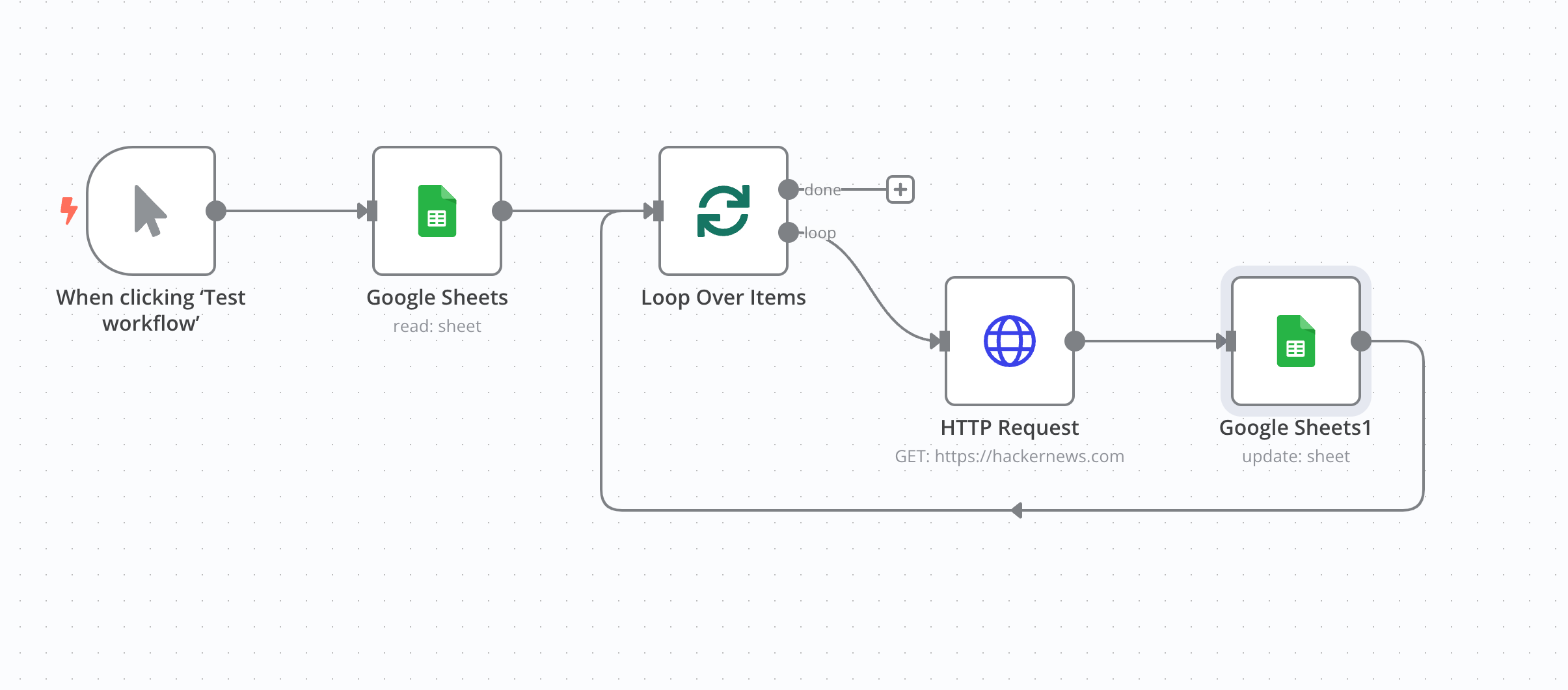
Let's say you are building a n8n screnario where you get website URLs from Google Sheet and request each URL via HTTP node or ScrapeNinja node, and put the HTML of the response back into Google Sheet. The naive approach would be to just add "Google Sheets (get all rows)" n8n node and "HTTP node" right after it. Let's say there are 100 URLs in your Google sheet. It is not obvious, but in this case n8n will run 100 HTTP requests at the same time. This can easily overload both the target website and you n8n instance. Even worse, if you want to store HTTP results somewhere, even if one of these HTTP requests fails, all the 100 HTTP requests results will be lost and next n8n node won't be executed. To mitigate this, always use built-in n8n Loop node when dealing with more than 10 external APIs or HTTP requests. Do not forget to put node which stores results in the same loop.
Best Practices for Production Scraping
When deploying scraping workflows to production, consider these tips:
-
Error Handling
- Implement comprehensive error catching
- Use n8n's error workflows
- Monitor scraping success rates
- Use n8n "Executions" tab on a scenario to see what is happening
-
Rate Limiting
- use Loop n8n node to limit concurrency
- Respect website terms of service
- Implement appropriate delays
- Use ScrapeNinja's built-in rate limiting features
-
Data Validation
- Verify extracted data integrity
- Handle missing or malformed data gracefully
- Implement data cleaning workflows
Conclusion
While n8n's HTTP node is perfect for basic web requests, serious scraping operations benefit significantly from ScrapeNinja integration. The combination provides a powerful, reliable, and scalable solution for modern web scraping challenges.
Remember: successful web scraping isn't just about getting the data - it's about getting it reliably, ethically, and efficiently. With n8n and ScrapeNinja, you have the tools to do just that.