Low Code Web Scraping Recipe: track Apple.com for refurbished iPhones and get push alert on specific model
Table of Contents
There is a number of projects which allow website monitoring, but I needed a pretty custom one - I wanted to check Apple.com refurbished section for iphone 12 models and get push notification to my phone when it is there. I also wanted pretty custom alerts - not email but a real push alert to my phone. I decided to build it with awesome tools: Make.com, ScrapeNinja and ntfy - and it took me around 20 minutes to get it running! I decided to pack my experience into this tutorial.
Step #1: The Task
Let's figure out what we want to do:
Apple currently don't have any iPhones 12 but has 11 models:
https://www.apple.com/shop/refurbished/iphone
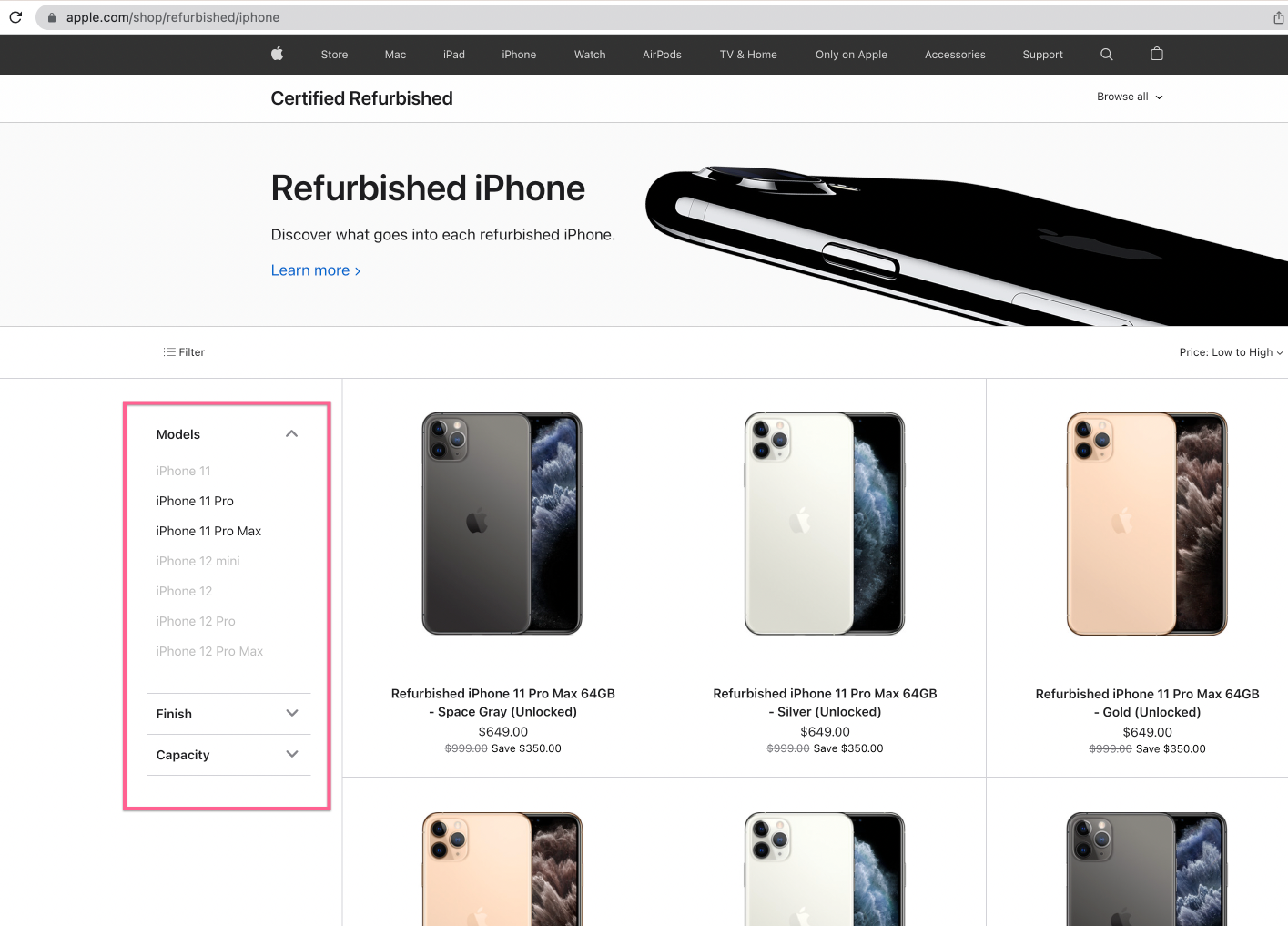
I want to get push notifications to my phone when iPhone 12 appears here.
What is the formal sign that iPhone 12 appears on the webpage? There might be multiple approaches, but here is mine: I extract the list of product titles on the page, and if in the list of products, there will appear at least one product title with "iPhone 12" in it, I want to trigger the alert logic.
Step #2: Tool Selection
Of course I could open VS Code and code everything from scratch using Node.js, as I am a seasoned software engineer. Even with my experience, this would take me, probably, from 4 to 8 hours - build good web page request (with retries), extraction logic testing, push notifications, and then I need to host it somewhere and make sure it does not go down and is working smoothly 24/7.
But I am lazy and effective, so I will use a low-code approach instead, and I will cut the development time from hours to minutes:
For web scraping heavy lifting, I will use ScrapeNinja. ScrapeNinja is a SaaS for web scraping, with a nice online tooling. I will need a free subsciption plan for ScrapeNinja.
For high-level business logic, I will use Make.com no-code automation framework (free subscription plan is enough), which is basically a cheaper and more technical alternative to Zapier and IFTT, and it is easy to trigger ScrapeNinja scraping request on schedule and then..
Send push notifications to my phone via awesome and minimalistic ntfy.sh service which is a free service (with android app for push notifications).
Step #3: Research. Using Chrome Dev Tools for Web Scraping
Let's explore the web page which we are going to scrape:
https://www.apple.com/shop/refurbished/iphone
I highly recommend to use Chrome Dev Tools, which is a built-in IDE in Chrome, to see the HTML of the web page and inspect DOM elements on this HTML web page. To open Chrome Dev Tools, right click on some element of the web page and choose "Inspect" or just click CMD+Option+I:
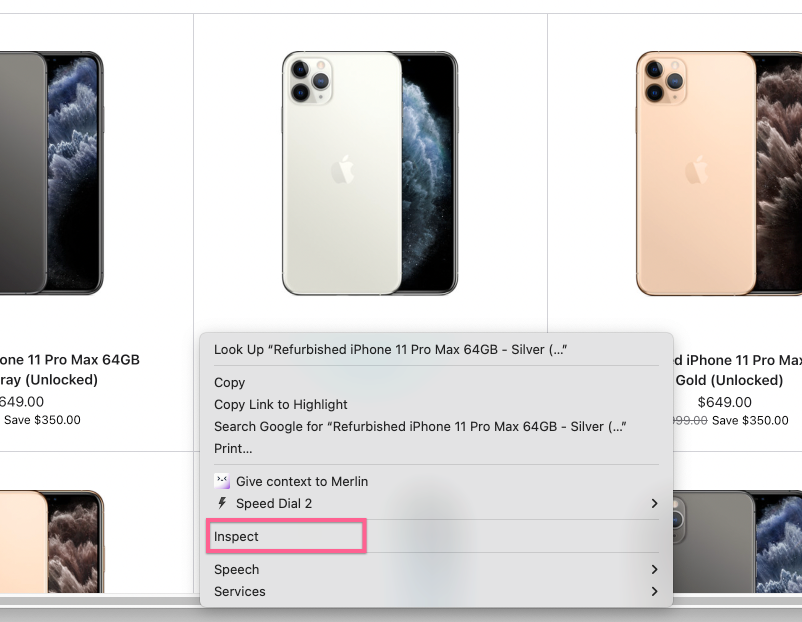
To quickly find the HTML element in huge HTML document, use arrow tool from Chrome Dev Tools:
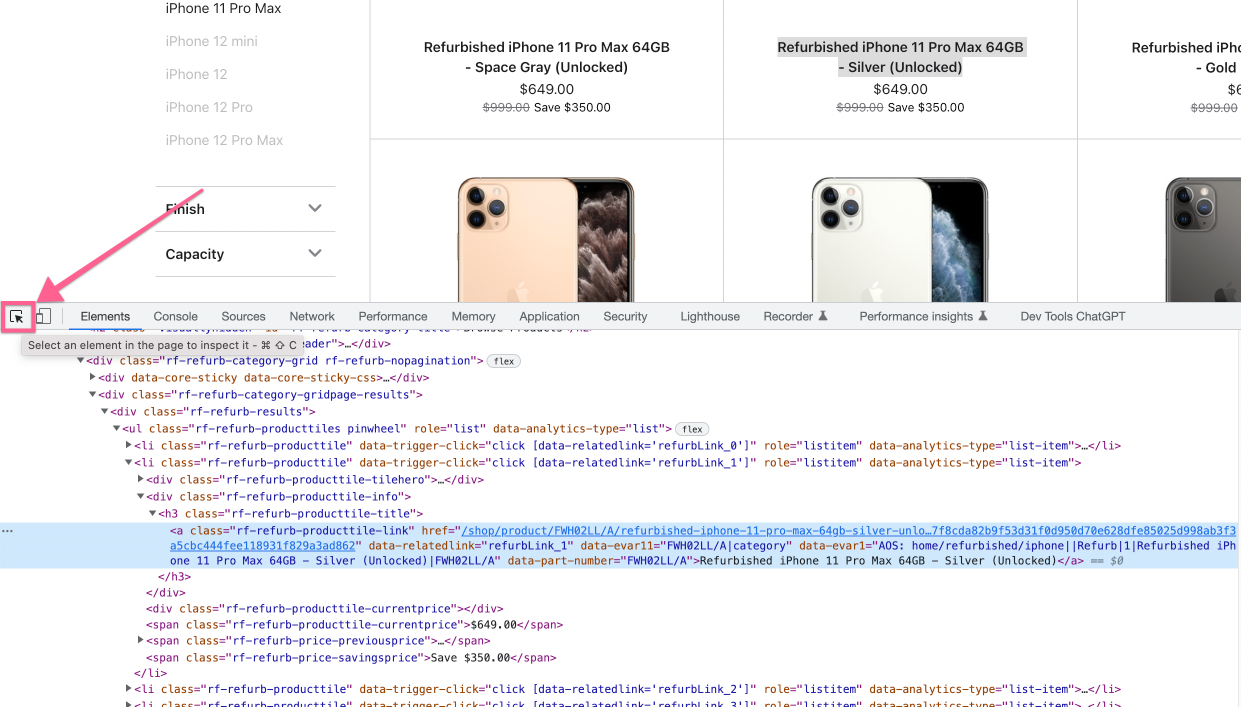
Step #3.1. In web scraping, what you see is NOT what you get: 2 web scraping modes
This is the hardest part of all the tutorial. Don't worry, this confuses everyone who just starts digging into web scraping: you need to understand that raw network requests and what you see in your browser is a very different thing.
When executing the web scraping request, the web scraper tool sees "raw" network html. In a lot of cases, this raw HTML is augmented by frontend Javascript frameworks which are executed in your browser.
Raw network requests to Apple.com return HTML page which differs from what you see in browser.
So, we have two options:
1) we make ScrapeNinja behave like a real web browser (by checking "Evaluate JS" checkbox on ScrapeNinja playground) - this might look convenient at first glance, but from my experience, this will be very slow for web scraping, and this request will be much more flaky and error prone, or...
2) we dumb down our Chrome to see how raw network response of Apple.com web page looks like, and dissect and analyze this raw HTML, which allows us to build a web scraper which is 10x faster and is 10x more reliable.
While ScrapeNinja can execute Javascript like a real browser, this makes the web request execute much slower, so you want to avoid this if possible. For apple.com, after some experimenting, I choose the second route, and to see how Apple.com renders the web page without Javascript, I go to Chrome Dev Tools and disable Javascript execution in my Chrome:
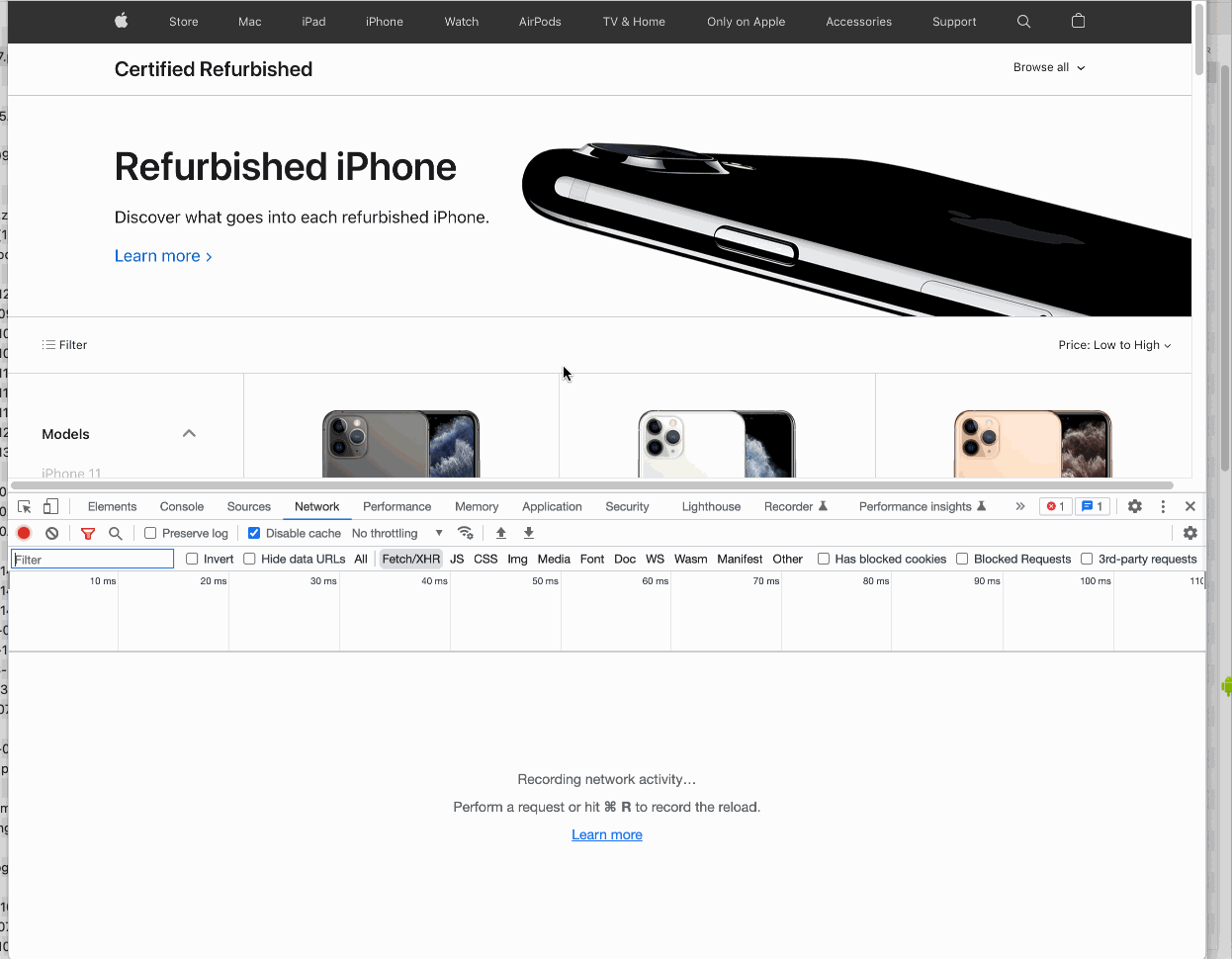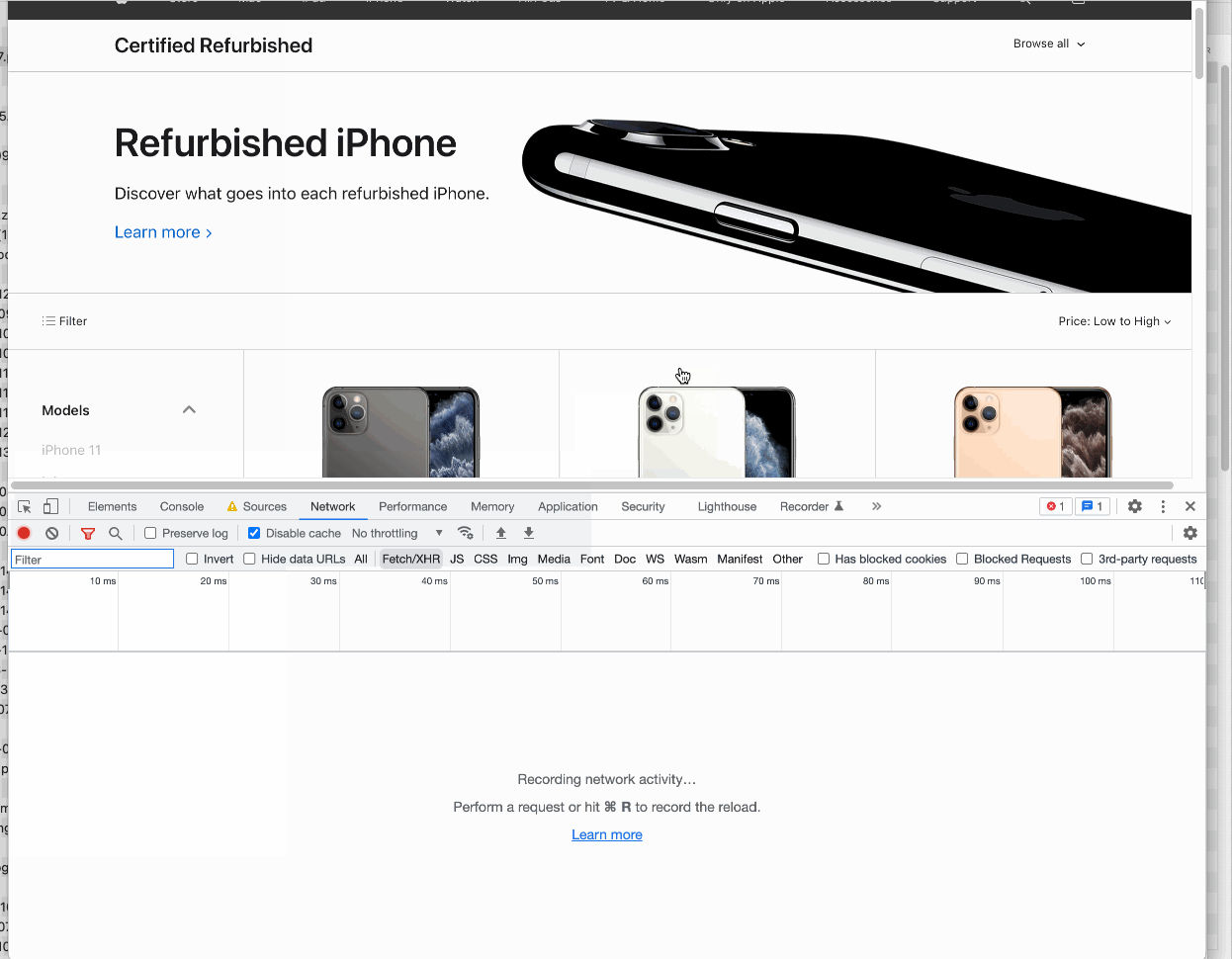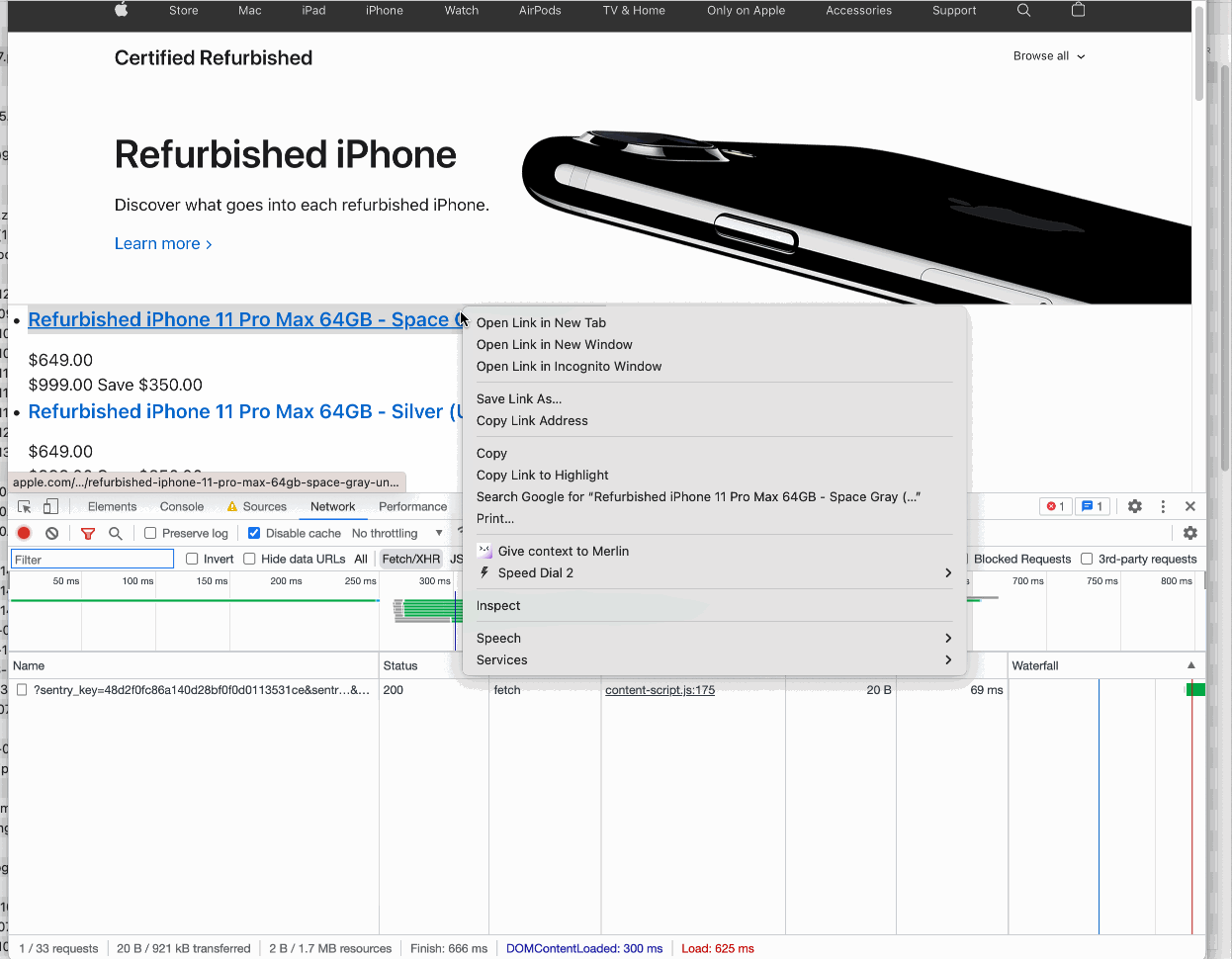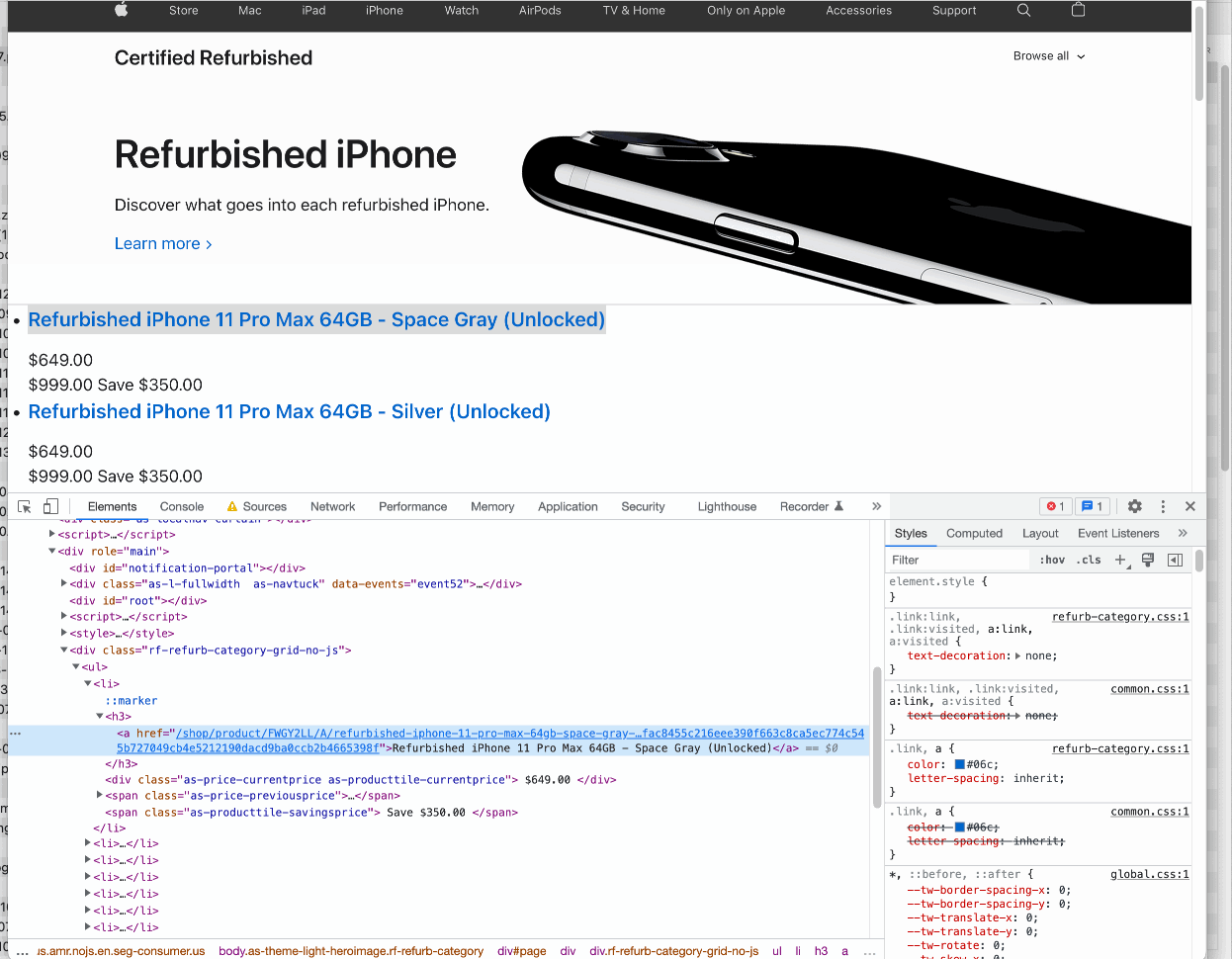
Perfect! So, there is a list of iPhones in raw HTML of Apple.com, but there is no left sidebar. We can work with that.
Step #3.2. Choosing DOM elements and extracting them
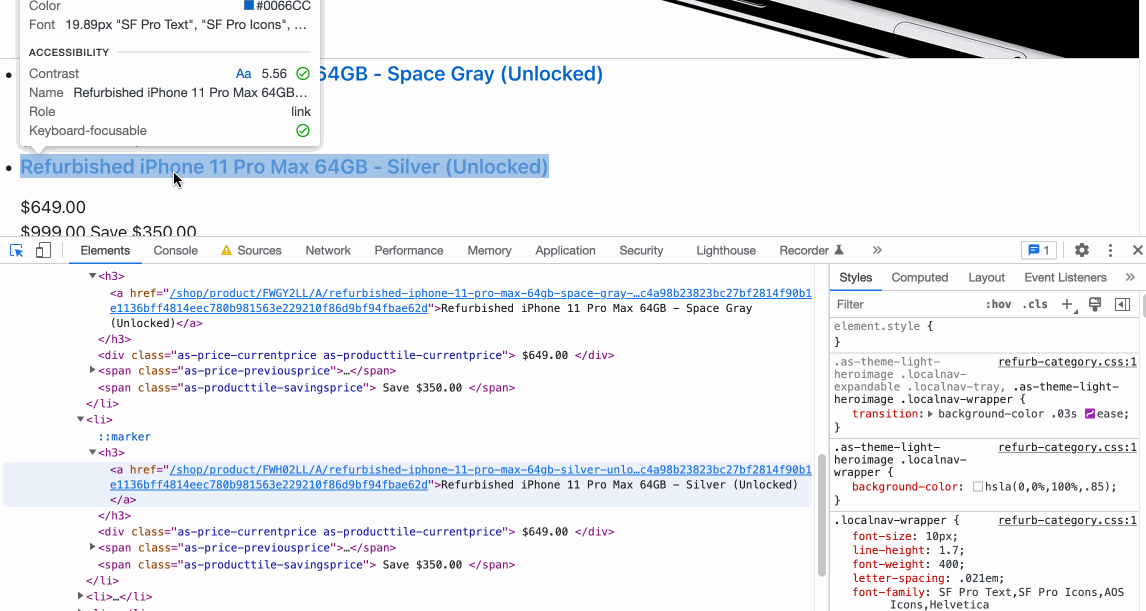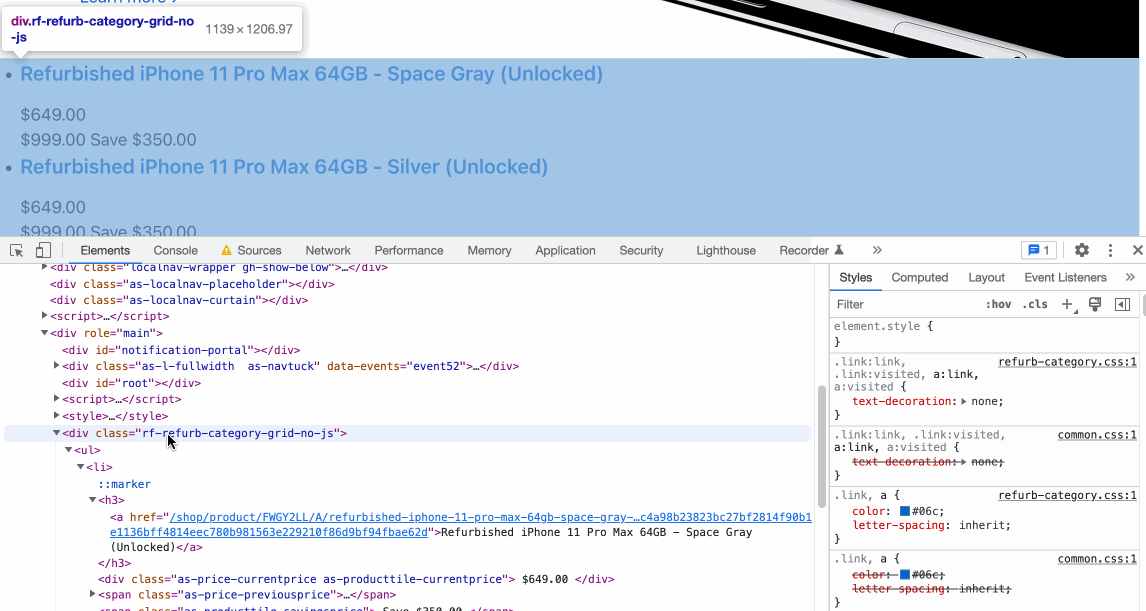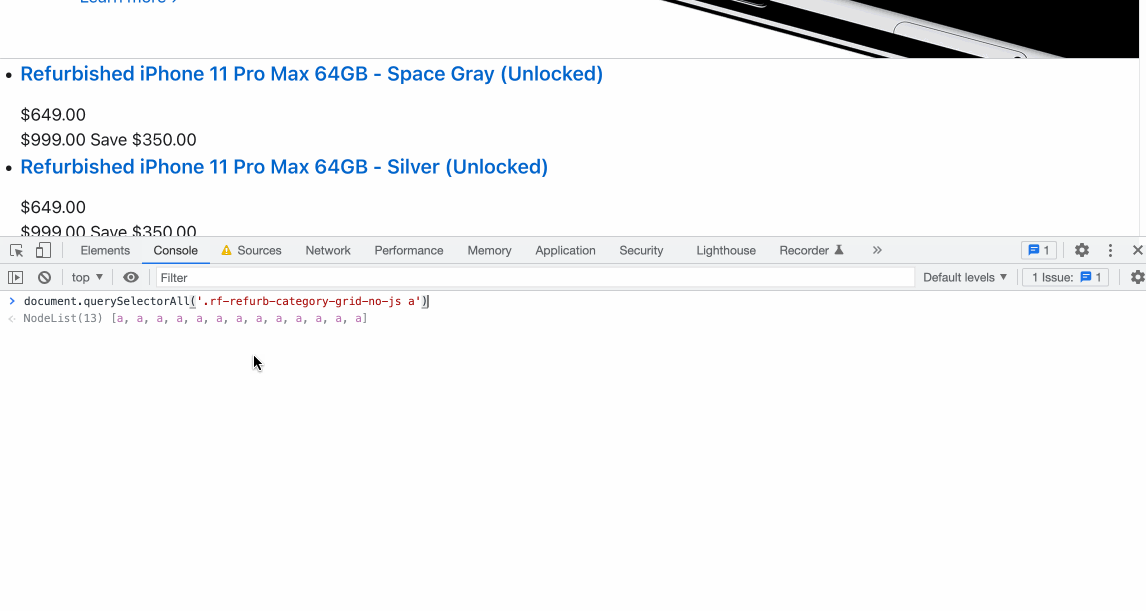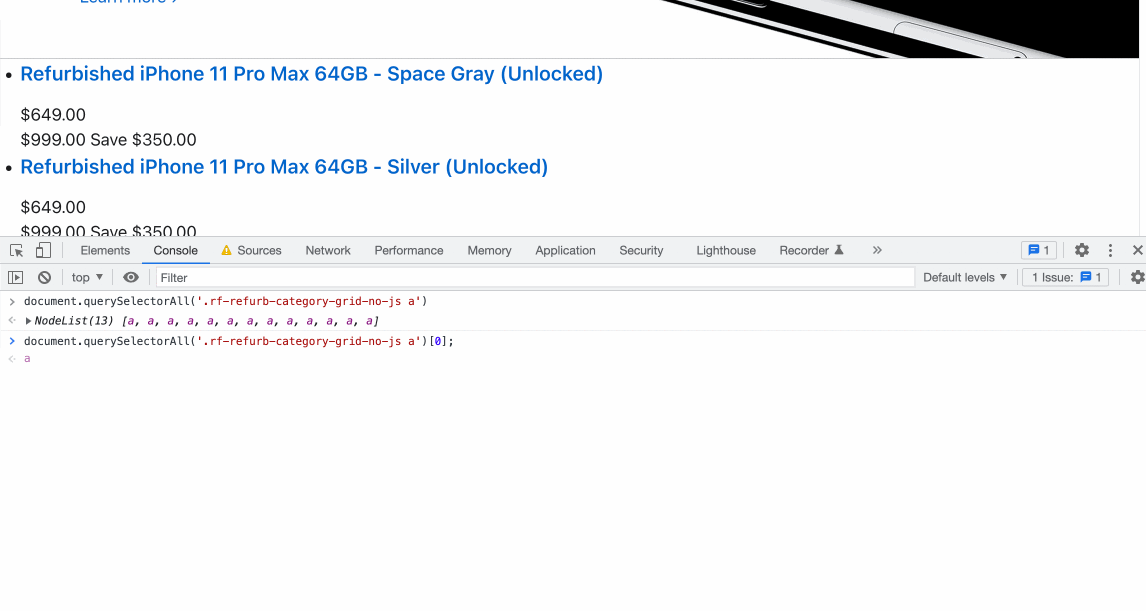
Using Chrome Dev Tools, we can quickly test how ScrapeNinja will extract the data.
Open console and write this: document.querySelectorAll('.rf-refurb-category-grid-no-js a')[0])
I have chosen .rf-refurb-category-grid-no-js class after checking HTML of the Apple.com web page.
Step #4: Using ScrapeNinja to Execute Scraping Request
Now I am heading off to ScrapeNinja.net online playground to quickly test my web scraping requests.
ScrapeNinja is a web scraping SaaS which allows to quickly extract JSON data from arbitrary web pages.
Here is the recipe I came up for Apple.com with after 15 minutes of experimenting:
https://scrapeninja.net/scraper-sandbox?slug=apple-refurbished-iphones (click "Scrape" button to execute the request right in your browser)
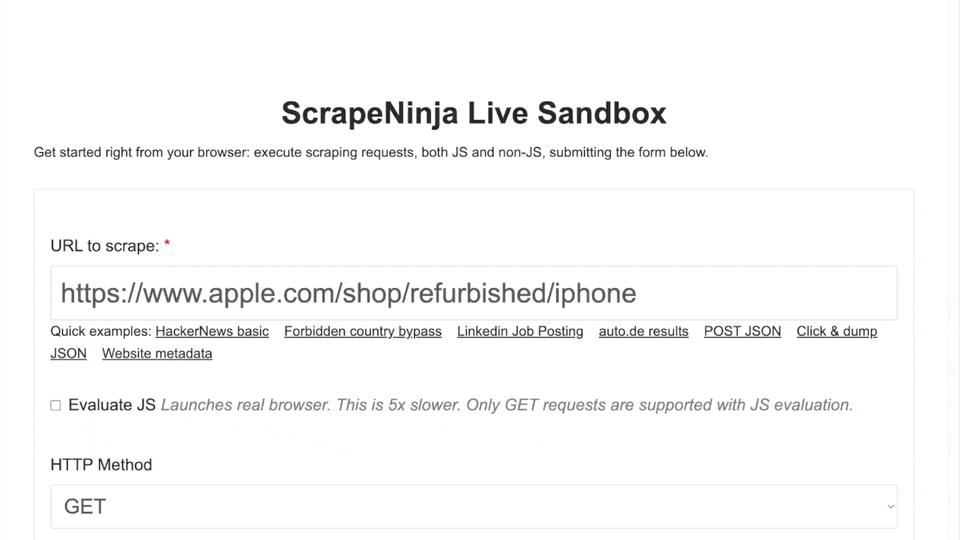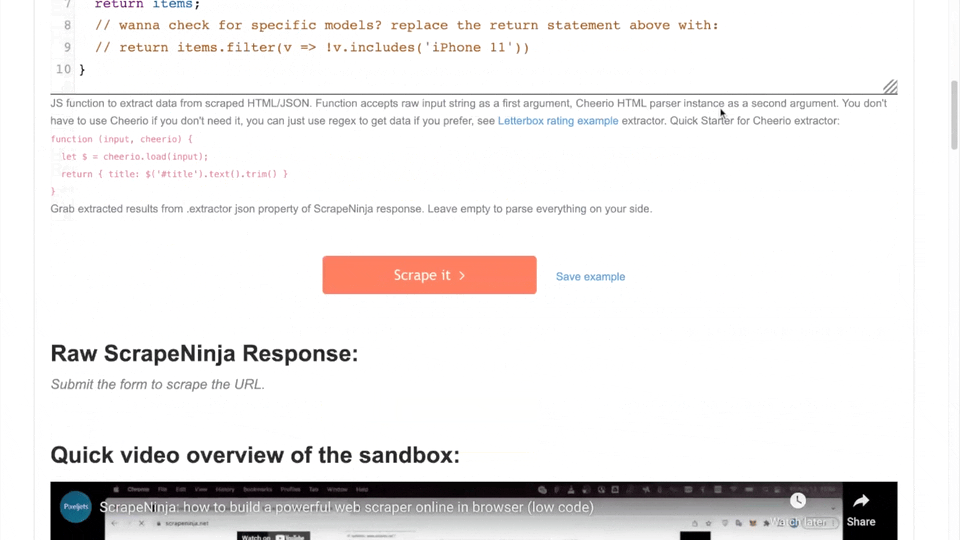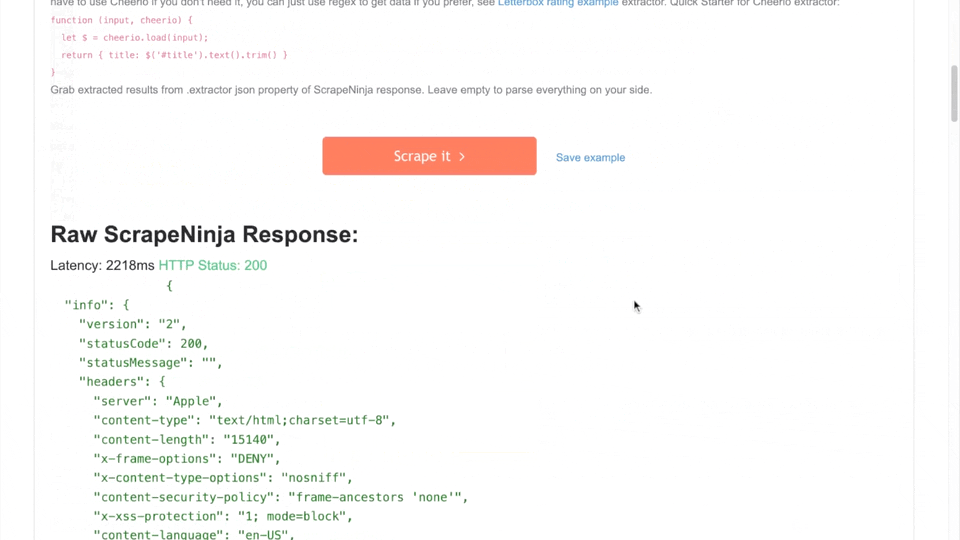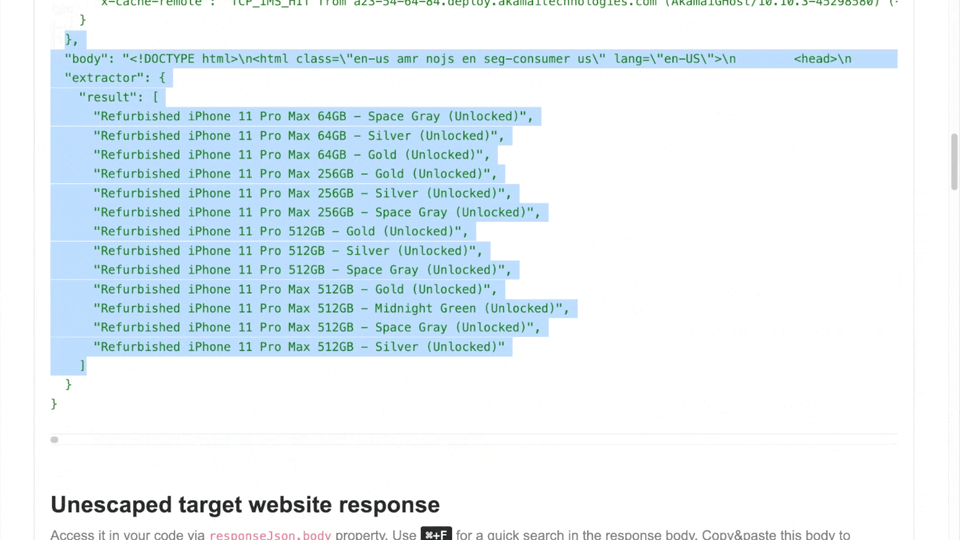
Key takeway is that Apple.com uses Akamai bot protection and it does not always return good web page, sometimes it returns 403 "access denied". So I have added 403 and 502 http statuses into retry section of ScrapeNinja which means the web request is retried from another machine in case ScrapeNinja sees these http errors on target website response.
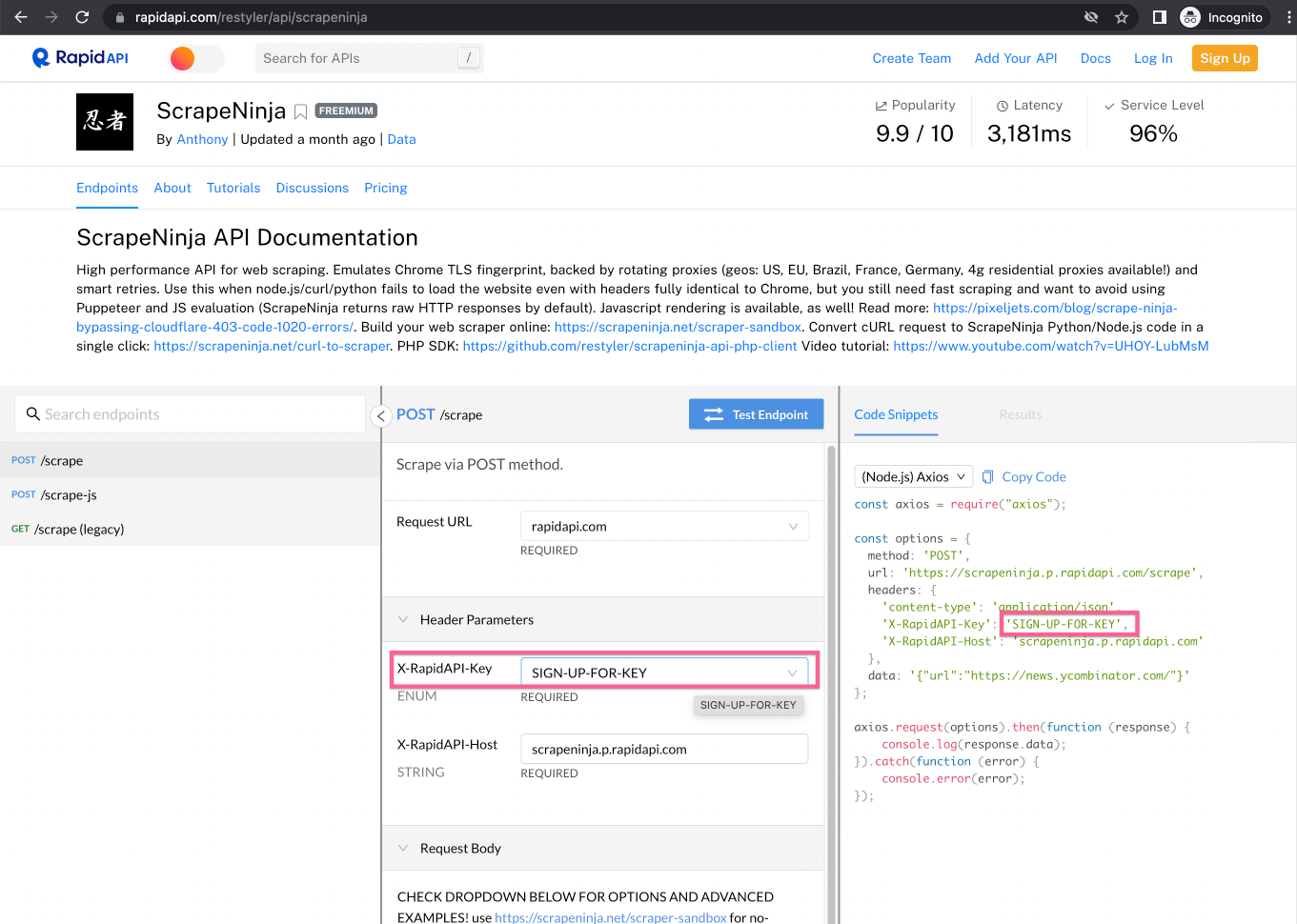
While ScrapeNinja Playground does not require an account, to execute scraping requests via ScrapeNinja in a real project, we need to create an account on RapidAPI and subscribe to ScrapeNinja, and get ScrapeNinja API key for later usage:
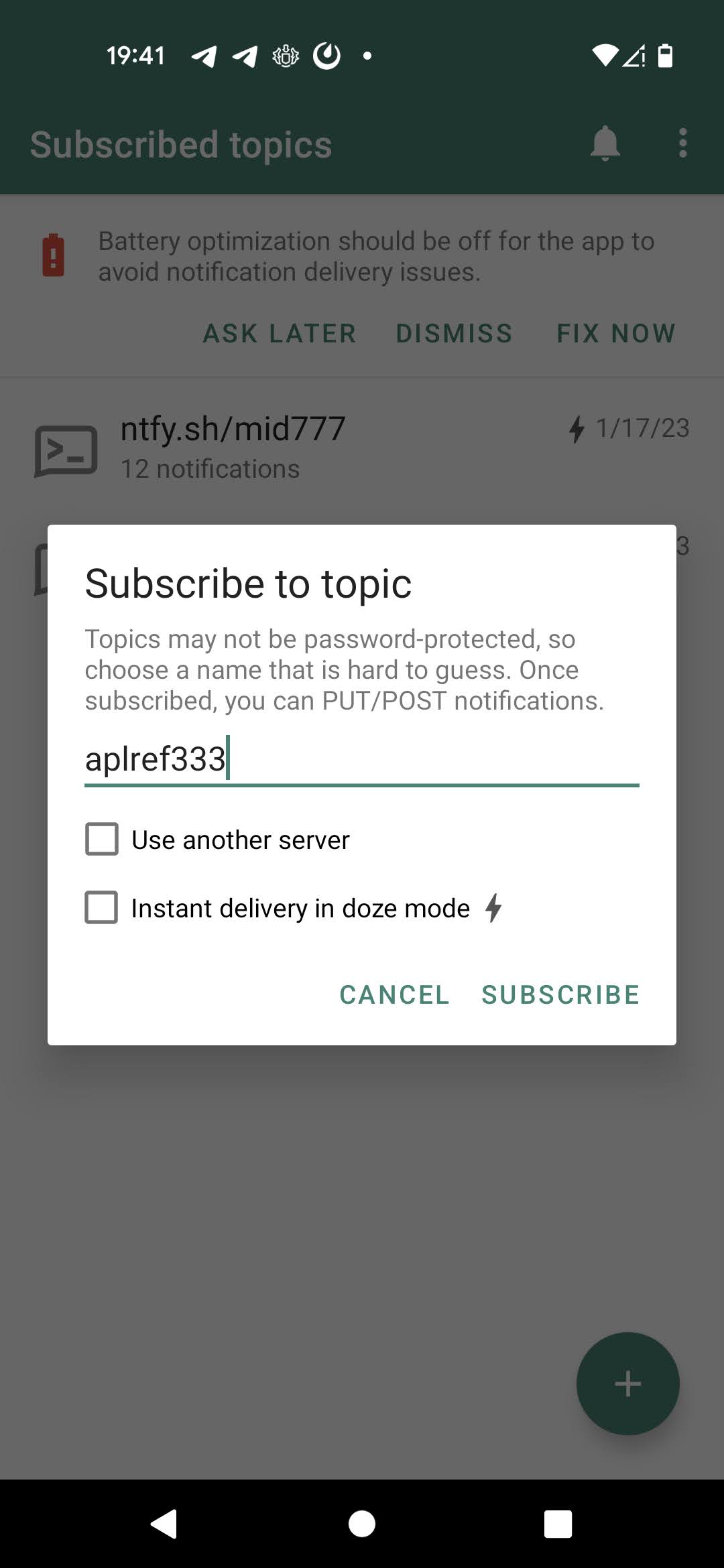
Step #5. Setting up ntfy.sh for alerts
Go to ntfy.sh and install its android app on your phone. Choose some topic (which is a random string that you generate) and "subscribe" to this topic from ntfy.sh android app:
Step #6. Set up Make.com scenario to glue everything together
Go to make.com and create you account, then create new scenario.
Click this link to get ScrapeNinja Make module: https://eu1.make.com/app/invite/6a5739aa760491ee365289b800649846
Don't forget to subscribe to ScrapeNinja and get your RapidAPI key for the subscription from RapidAPI web page.
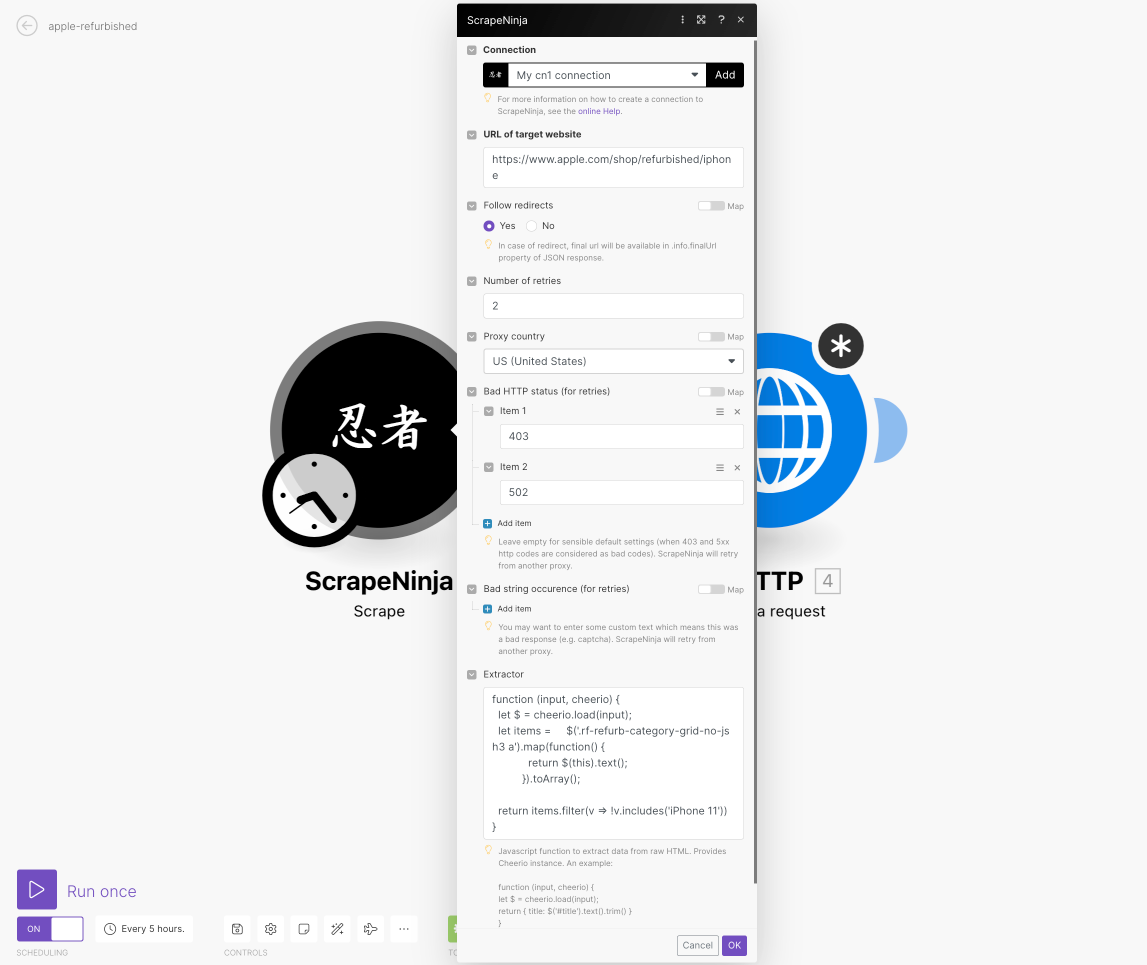
create new action: ScrapeNinja scrape, like on the screen:

First action is ScrapNinja /scrape action:
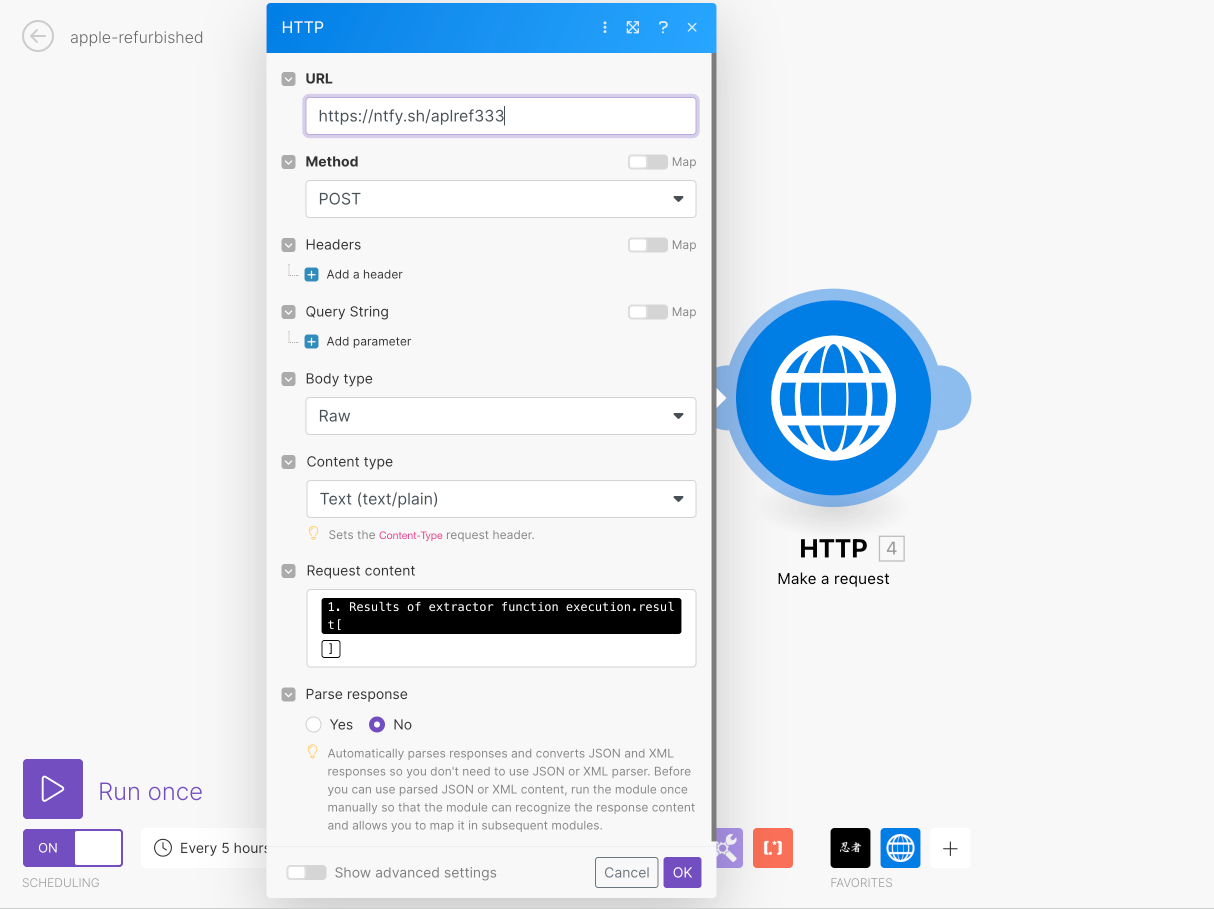
Second action is HTTP request to ntfy.sh:
now let's schedule the scenario to be run every one in a while:
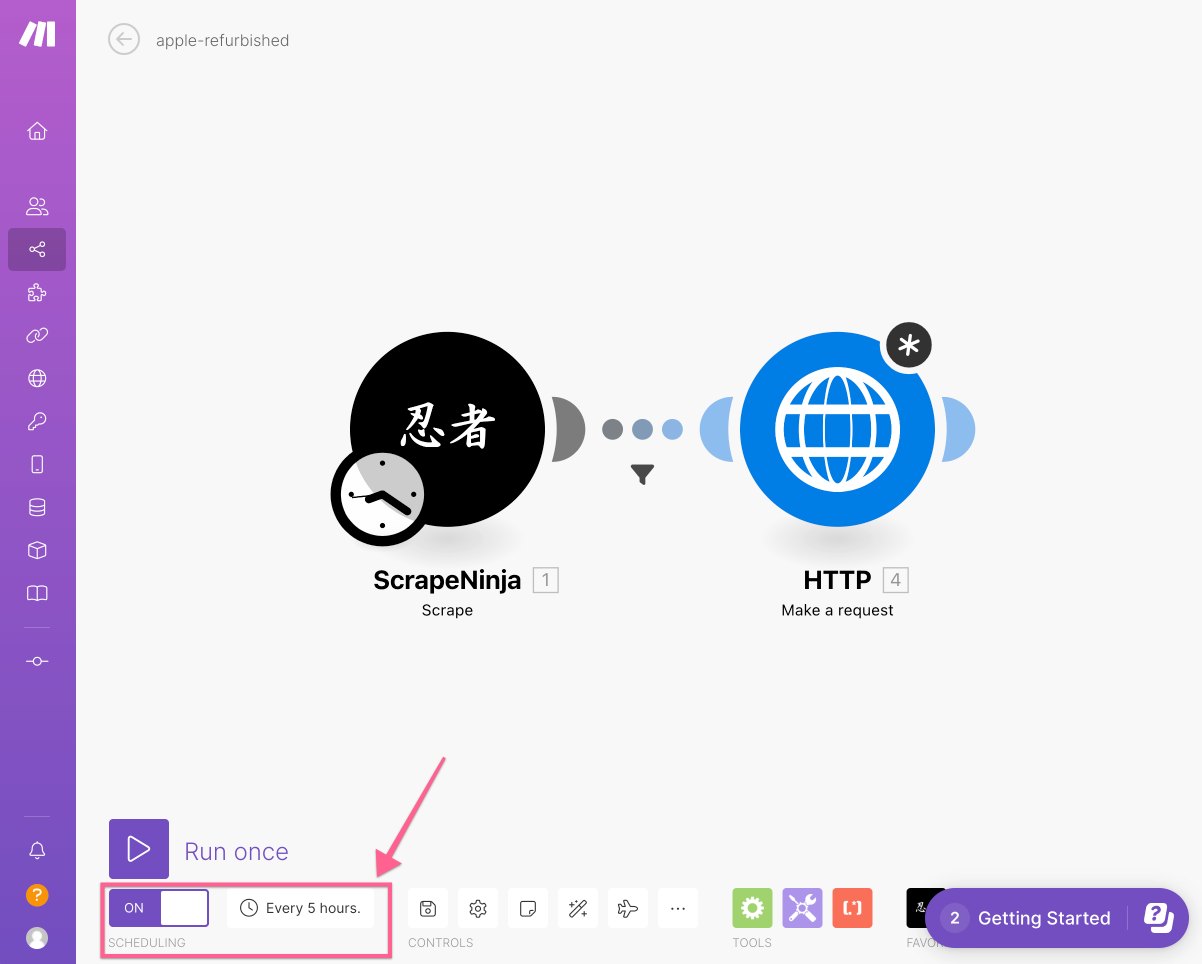
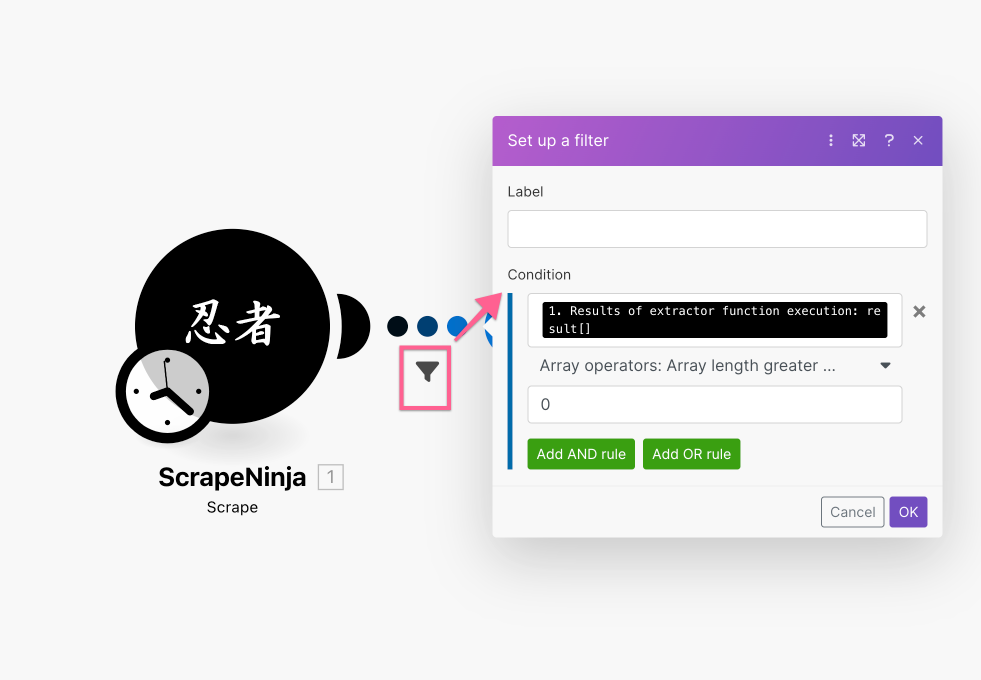
I also need to make sure the push notification is not triggered in case ScrapeNinja extractor return empty array, so I set up filter between two actions:
Step #7: testing everything out
To test everything, we need to trigger Make.com scenario like it would trigger when Apple finally puts iphones 12 on its refurbished page. To do this, let's modify the extractor part of ScrapeNinja:
function (input, cheerio) {
let $ = cheerio.load(input);
let items = $('.rf-refurb-category-grid-no-js h3 a').map(function() {
return $(this).text();
}).toArray();
// return all items
return items;
// wanna check for specific models? replace the return statement above with:
// return items.filter(v => !v.includes('iPhone 11'))
}and click "Run once" in Make.com scenario builder:
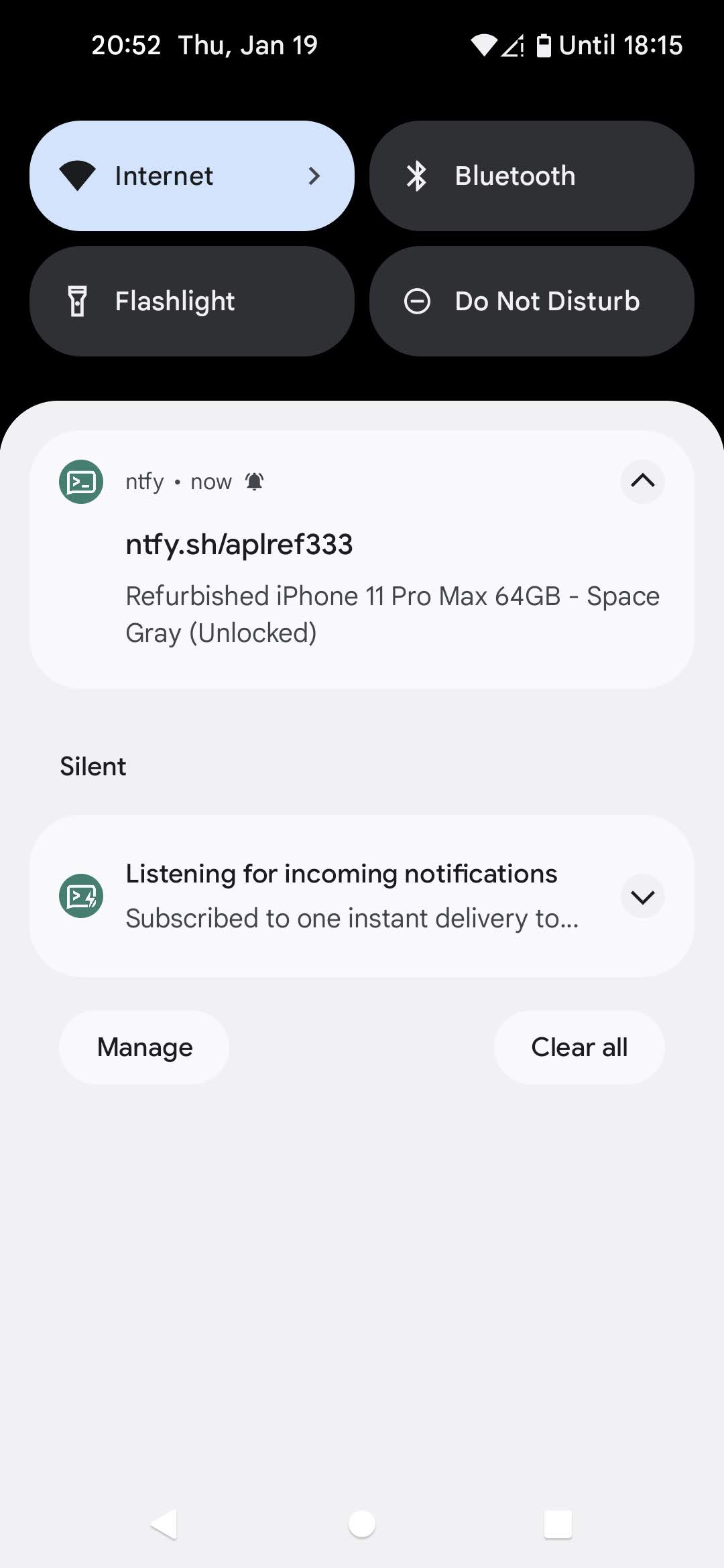
Hooray! We got a nice push notification with first product title in it.
Congratulations, we've just built a pretty complicated scraper, which is very flexible. Using similar approach, a huge amount of real world tasks can be accomplished. See my video on how I extract data from websites and put it into Google Sheets: