Web scraping in Javascript: node-fetch vs axios vs got vs superagent
Table of Contents
There is a number of ways to perform web requests in Node.js: node-fetch, axios, got, superagent
Node.js can perform HTTP requests without additional packages
While I don't ever use this approach because of it's poor developer ergonomics (using EventEmitter to collect the response data is just too verbose for me), Node.js is perfectly capable of sending HTTP requests without any libraries from npm!
const https = require('https');
https.get('https://example.com/some-page', (resp) => {
let data = '';
// A chunk of data has been received.
resp.on('data', (chunk) => {
data += chunk;
});
// The whole response has been received. Print out the result.
resp.on('end', () => {
console.log(JSON.parse(data).explanation);
});
}).on("error", (err) => {
console.log("Error: " + err.message);
});Tip: require the https module instead of http module if the target URL communicates over HTTPS.
Pros: zero dependencies.
Cons: very verbose and ugly callbacks instead of promises. These resp.on('data') and resp.on('end') callbacks are fun to write only if you have one or two requests in your whole project. It is not possible to use the async/await for the HTTP requests made with this library, you could potentially use asynchronous streams for chunking the data.
node-fetch
Github: https://github.com/node-fetch/node-fetch stars: 8k
Installation:
npm i node-fetch
Node-fetch is a lightweight package to perform HTTP(S) requests in Node.js. It is definitely the most minimalistic package in this post. Node-fetch was inspired by client-side browser Fetch functionality and these two have the same API surface. It is important to understand that Node v18 introduced native fetch API so if you are not planning to use Node versions less than v18 – you might consider using stock Fetch API instead of node-fetch.
import fetch from 'node-fetch';
const response = await fetch('https://api.github.com/users/github');
const data = await response.json();
console.log(data);Tip: node-fetch recently switched from old commonJS module to ESM.
If you still want to use require instead of import, you need to install version 2 of the package: npm i node-fetch@2
Pros: clean, concise, minimalistic, modern (no callbacks)
Cons: Very minimalistic :)
- no query string constructors, so you can't conveniently pass an object as a query string, which is sometimes convenient and is possible in higher level packages.
- no timeouts can be specified. You have to use some wrapper package for node-fetch to have timeouts, which is not too convenient. I have even built my own package for this.
- verbose proxy setup for the request
Axios
Github: https://github.com/axios/axios stars: 97.7K
Axios was initially developed for web browsers, but then received node.js support as well.
Pros: Feature rich! It is possible to cancel requests via AbortController, set timeouts, specify proxy using concise syntax. The concept of Interceptors which is like a middleware for requests is powerful and helps to write less code. Of course, promises and async-await are available in Axios out of the box. You can use Axios in browser and in node.js, same syntax for two very different environments! I am not sure I am a big fan of this, sometimes it might get confusing because browsers and Node.js still have very different feature sets, but this definitely helps to get started much faster in a lot of simple cases.
Cons: might be a bit too magical sometimes. For example, I consider sending POST data as non-serialized object as an overkill. It's hard to undestand what is really sent to the browser in this case - is it json or www-encoded data?
superagent
Github: https://github.com/ladjs/superagent stars: 16.2K
SuperAgent is the oldest Node.js request packages in my list, released in April 2011. A robust HTTP library for Node.js, SuperAgent brands itself as a “small, progressive, client-side HTTP request library and Node.js module with the same API, supporting many high-level HTTP client features.” It offers both callback- and promise-based APIs. With a promise-based API, using async/await is just some syntactic sugar on top of it.
SuperAgent also features an array of plugins, ranging from no-cache to measuring HTTP timings.
Installation
npm i superagentPros: feature rich. Extendable by plugins
Cons: I can definitely feel the age of this package by looking into its dependencies. For example, cache plugin for SuperAgent was not updated for years.
got
Github: https://github.com/sindresorhus/got stars: 12.4K
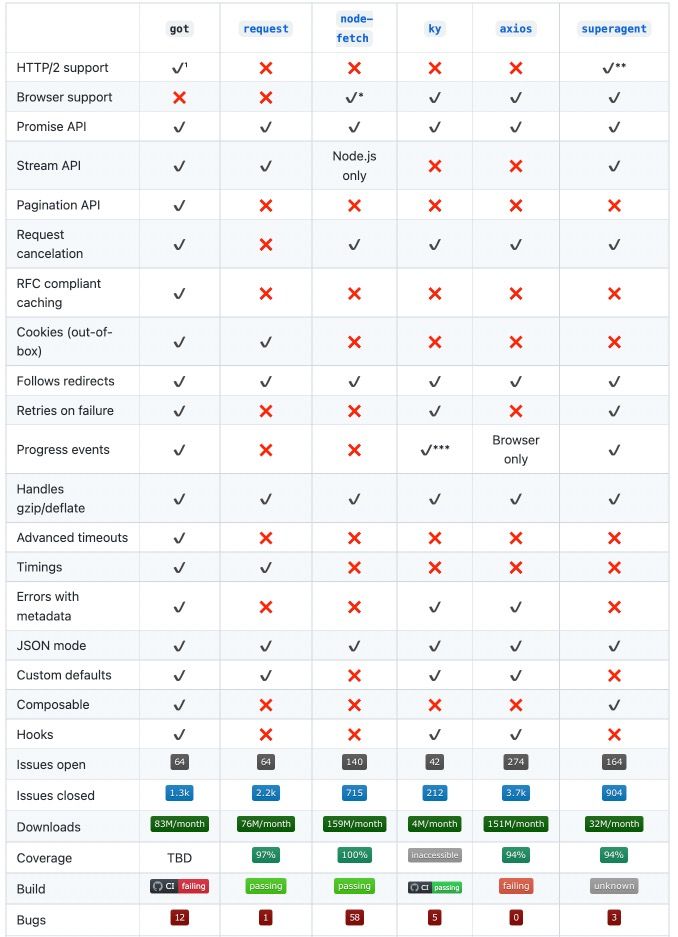
This is a feature-rich Javascript package with HTTP/2 and complex retries available in stock.
Got has a very nice comparison table of HTTP packages for node.js:
Installation
npm i gotUsage
import got from 'got';
const {data} = await got.post('https://httpbin.org/anything', {
json: {
hello: 'world'
}
}).json();
console.log(data);Pros: sophisticated retry strategies available out of the box, also very advanced timeout settings.
Cons: can't be used in browser, built for Node.js. Not sure if this is a bad thing, since HTTP requests differ vastly for Node.js and browser, anyways..
Request
Github: https://github.com/request/request stars: 25.6K
I am adding Request package to consider this list as complete, though this library was deprecated long-long time ago, and I do not recommend to use it.
Conclusion: which package to choose for Node.js HTTP(S) requests?
I think Got is the best package to use in modern server-side Javascript. It ticks important checkboxes:
- It is relatively modern (first class async-await and Promises) – without being "new kid on the block" which might be abandoned on the next month
- It has a lot of well-thought and well-tested features without being too modular, so I don't need to run another 5 npm installs to get pretty basic networking features like retries or timeouts (like superagent).
- It is pretty popular
- It allows to use most modern proxy package to set up proxies
In my 10-line node.js scripts I also tend to use node-fetch because I love minimalistic solutions, and node-fetch has zero magic and you can do everything with it.
So, node-fetch and got are doing 100% of my http requests in Node.js.
Unblockable web scraping in Node.js
Web scraping is Node.js is cumbersome, all these timeouts, retries, proxy rotation, bypassing website protections, and extracting data from HTML is a huge pain. After spending months of my life building Javascript web scrapers, I ended up re-using same patterns and copy&pasting my web scraping code again and again, and then I realized this might be useful for other people, as well. I have built and bootstrapped ScrapeNinja.net which not only finally made my life a lot easier, but also helped hundreds of fellow developers to extract web data! I now build and test all my web scrapers in browser, spending minutes instead of hours, and then I just copy&paste generated Javascript code of the web scraper from ScrapeNinja website to my node.js server so it can safely run in production. Try ScrapeNinja in browser and let me know if it helps you, too.