Running untrusted JavaScript in Node.js

Table of Contents
ScrapeNinja Scraping API recently got an exciting feature called Extractors. Extractors are pieces of user-supplied Javascript code which are executed in ScrapeNinja backend so ScrapeNinja returns pure JSON with data, from any HTML webpage in the world. This feature alone, with ScrapeNinja web-based IDE do write extractors, can shave off hours of development & testing when building a web scraper. Here is a demo of extractor feature which turns HackerNews HTML frontpage into pure JSON of posts:
https://scrapeninja.net/scraper-sandbox?slug=hackernews
and here is the corresponding extractor:
// define function which accepts body and cheerio as args
function extract(input, cheerio) {
// return object with extracted values
let c = cheerio.load(input);
return {
items: c('.title > a:not(.morelink)').map(function() {
let infoTr = c(this).closest('tr').next();
return {
title: c(this).text(),
url: c(this).attr('href'),
user: infoTr.find('.hnuser').text(),
points: parseInt(infoTr.find('.score').text()),
createdAt: infoTr.find('.age').attr('title')
}
}).toArray()
};
}Disclaimer: no, it does not make any sense to scrape HackerNews in real world because they have an API!
The problem
ScrapeNinja Cloud Scraper API is a SaaS which is targeted at developers audience and is designed to be integrated into higher-level scrapers/spiders developed by ScrapeNinja customers. It solves the task of properly and reliably retrieving the HTML/JSON from target websites, with retries, optional JS rendering, optional human interaction emulation, and proxy rotation. ScrapeNinja was useful enough to gain traction and got its first customers, but every time I used my own product I enjoyed that ScrapeNinja removed the burden of retrieving target website output, and at the same time I suffered when I needed to extract data from HTML. Installing cheerio, and remembering cheerio syntax, saving test input HTMLs to project folder, and re-running my extraction code across test HTML outputs on every small scraper was taking too much time. This led me to the conclusion that my customer base might also suffer from this. So, the idea was to make ScrapeNinja able to extract pure JSON data from any HTML by itself, to further reduce friction on developing web-scraper and integrate simple cheerio extraction JS code into ScrapeNinja API call. This also allowed to integrate ScrapeNinja into no-code and low-code solutions which are perfectly capable of executing HTTP API calls and are good working with JSON, but might have issues installing and executing cheerio or any other extraction libraries.
When building ScrapeNinja JS extractor feature, I had to solve an exciting engineering problem of running untrusted JS.
4 ways of executing user-supplied JavaScript in Node.js
Eval()
This is the easiest way and obviously it is also the shortest route possible to a disaster. Any process.exit() run by malicious user will kill your node process. Never use eval() to run untrusted code, period.
VM
https://nodejs.org/api/vm.html
Official Node.js documents state: "The node:vm module enables compiling and running code within V8 Virtual Machine contexts. The node:vm module is not a security mechanism. Do not use it to run untrusted code."
This way seems to be much better than just evaling the custom code, but is still a bad idea. It is so unfortunate the official docs do not, even briefly, state or leave any pointers on what might be the correct way to run untrusted code, huh?
isolated-vm
https://github.com/laverdet/isolated-vm
This projects looks pretty robust, but I have discovered it after VM2 so I didn't look into it too deep because my mental budget allocated on the whole "run-untrusted-js" research was already almost exhausted.
isolated-vm is used by Algolia in their custom crawlers and by Fly CDN for their dynamic endpoints
isolated-vm is the only real sandbox which leverages low-level V8 engine Isolate Interface, among all 4 ways mentioned in this blog post. While isolated-vm itself might not be used but the same underlying Isolate approach is what powers CloudFlare workers and Deno Deploy:
- https://developers.cloudflare.com/workers/learning/how-workers-works/
- https://deno.com/blog/anatomy-isolate-cloud
Its API seems more complex to grasp than the API surface of VM2, but in most of cases this is a low price to pay for the best security and performance, out of all ways to execute untrusted JS code in node.js. isolated-vm is also not too popular in terms of amount of downloads, compared to VM2 which has orders of magnitude more downloads. I liked that isolated-vm has memory limiting feature and they also have nice alternatives comparison table:
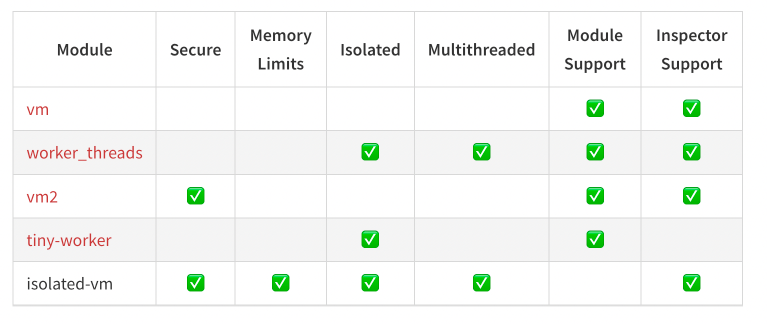
I might consider using V8::Isolate approach later but for now I decided to keep it simple and not over-think the performance part. I was also hesitant to use vm-isolated because I felt I might have to spend a lot of hours launching cheerio in this perfectly isolated context (I might be wrong!).
VM2
https://github.com/patriksimek/vm2
Project description: vm2 is a sandbox that runs untrusted code with whitelisted Node's built-in modules. Securely!
VM2 project is what I have used in ScrapeNinja. I liked the balance of its API simplicity, performance, and security. VM2 author and maintainer Patrik Simek is actually the CTO of Integromat (now renamed to Make), which is a pretty big player in low-code automation space and is a healthy competitor of Zapier.
If you google "vm2" you will quickly encounter fresh news headlines:
A remote code execution vulnerability has been identified in a widely used JavaScript sandbox. The vulnerability has earned a rating of 10, the highest number on the CVSS vulnerability scale. Therefore, the bug is described as high severity. The flaw could allow threat actors to execute a sandbox escape and run shell commands through the hosting machine.
The vulnerability was identified by researchers from the firm Oxeye. The vulnerability was found in vm2, which is a JavaScript sandbox with over 16 million monthly downloads. The severity of the vulnerability and the popularity of the application it was found in means that the potential impact could be wide and critical, Oxeye says. The flaw was identified on August 16 and reported to the project owners two days later.
Here is the GitHub Security Advisory: https://github.com/advisories/GHSA-mrgp-mrhc-5jrq and here is the GitHub issue with the proof of concept for the exploit: https://github.com/patriksimek/vm2/issues/467
Luckily, ScrapeNinja was already running updated vm2 version when all these news started coming. Hopefully, there are no zero-day vulnerabilities in vm2 now, because 16M downloads per month is massive. But, even if I used outdated version of vm2, and some malicious actor uploaded exploit which could escape vm2 context, to ScrapeNinja extractor, the attack surface on ScrapeNinja infra was not big, because I containerized the node instance running vm2.
Running untrusted code safely is not an easy task, apparently!
Implementation details
After spending a couple of hours reading vm2 issue queue on Github, I realized that just executing vm2 in the same process space which runs main ScrapeNinja node.js code is.. well, is somehow resembling a suicide. I won't pretend that I have read and understood all the VM2 source code, but from what I've seen, VM2 is just using node:vm and is "patching" node.js global objects to make it hard for the untrusted code to escape and execute some dangerous stuff, and since the whole approach mostly looks like putting patches on a leaky bucket (with a lot of holes in it), vulnerabilities and exploits might probably arise in a future. Github issue discussing differences between vm2 and vm-isolated. So, consider vm-isolated which, as mentioned above, uses V8::Isolate, if you need better security.
Fun fact: I actually didn't know about this critical vulnerability mentioned above, at the time when I was taking all architecture decisions for ScrapeNinja, so looking into the past now I am a bit proud of myself because I went an extra mile here during initial feature design, and it turned out this extra mile was indeed necessary. Here is the architecture which keeps ScrapeNinja running:
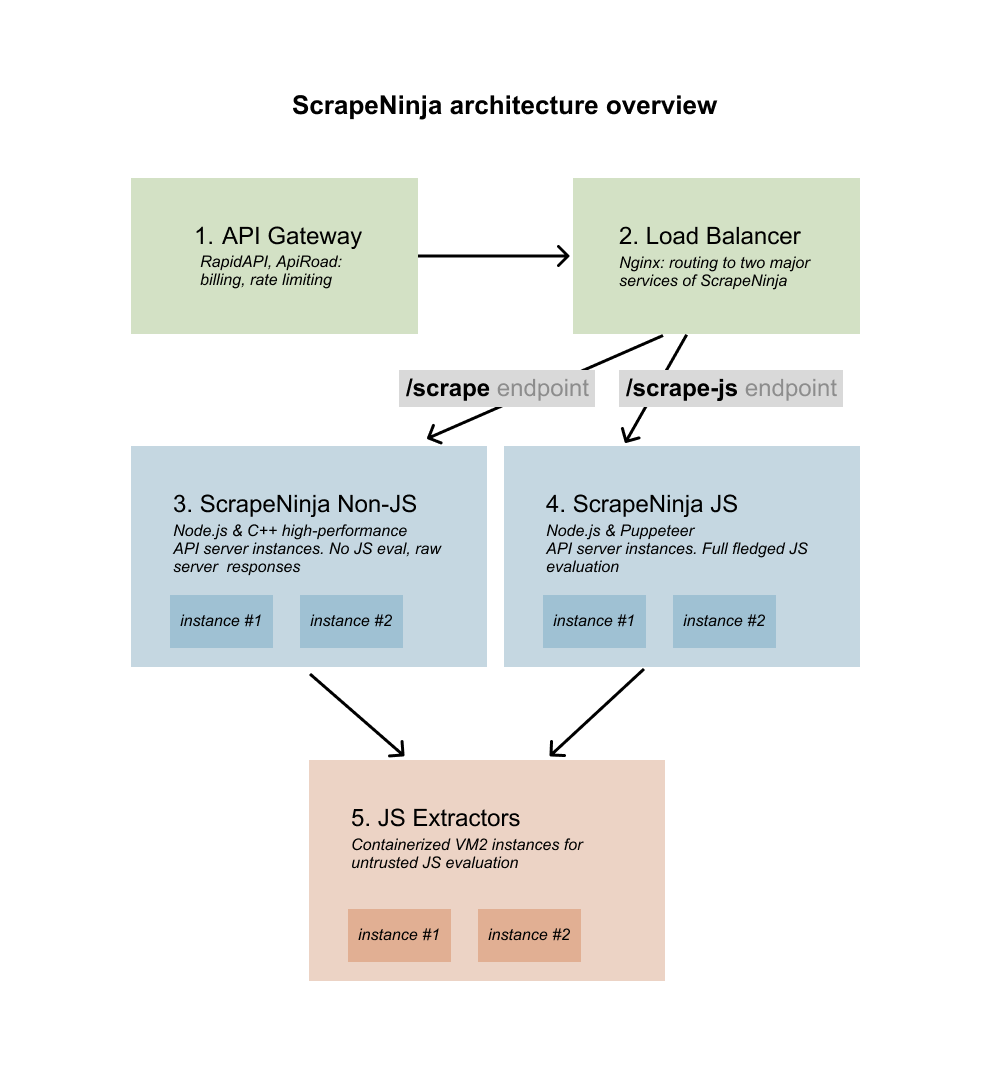
Since JS extractors service (fig. 5) executes a pretty tiny functions (thousands times per minute) which need to interact with main ScrapeNinja instances (figures 3 and 4) I decided to look into possible alternatives to good old REST API over HTTP protocol.
Choosing between ZeroMQ and HTTP REST for Node.js inter-process communication
ZeroMQ has Node.js bindings and if you don't know ZeroMQ, it is basically some syntax sugar and a bunch of magic tricks on top of TCP, which makes writing lower level network apps more enjoyable. I wanted to go to lower level networking in Node.js for a long time, and this was a good chance!
ZeroMQ (also known as ØMQ, 0MQ, or zmq) looks like an embeddable networking library but acts like a concurrency framework. It gives you sockets that carry atomic messages across various transports like in-process, inter-process, TCP, and multicast. You can connect sockets N-to-N with patterns like fan-out, pub-sub, task distribution, and request-reply. It's fast enough to be the fabric for clustered products. Its asynchronous I/O model gives you scalable multicore applications, built as asynchronous message-processing tasks. It has a score of language APIs and runs on most operating systems. https://zeromq.org/
This looked like a good idea at first. But honestly, the overhead of HTTP and REST is so low, that after running some basic benchmarks it became clear that it does not make a lot of practical sense - ok, HTTP "hello world" tests might be 10-25% slower than ZeroMQ (couldnt find good benchmarks on internet, but here is one), but this is highly unlikely that this might ever be a bottleneck for ScrapeNinja extractors because cheerio and vm2 overhead is just orders of magnitude more significant for overall extractor execution time. And using zeromq instead of REST means I lost a lot of conventions and convenience which I am so used to. For example, when I wanted to quickly test my zeromq extractors server by sending serialized JS functions over the wire, I couldn't even use my favorite VS Code extension for REST API requests which was a big downside. Heck, I couldn't even use cURL because cURL is good for HTTP requests, not for custom TCP requests! So I had to write custom js tests which used zeromq client lib, to launch requests to zeromq server. I think I will get rid of zeromq in ScrapeNinja and rewrite everything to REST, but for now the communication between microservices still uses zeromq.
The Code
ScrapeNinja servers (which are "client") have extract() function which looks like this:
Client
import zmq from "zeromq";
const connect = (addr) => {
let sock = new zmq.Request({ relaxed: true, correlate: true, sendTimeout: 1000, receiveTimeout: 2000 });
sock.connect(addr);
console.log(`connection created to ${addr}`);
return sock;
}
export async function extract (input, extractor) {
const EXTRACTOR_HOST = process.env.EXTRACTOR_HOST ?? "tcp://127.0.0.1:3000";
let sock = connect(EXTRACTOR_HOST);
let resultObj, errMsg, errMultiline;
let start = new Date;
try {
await sock.send(JSON.stringify({ input, extractor }));
const [result] = await sock.receive()
console.log(result.toString())
resultObj = JSON.parse(result.toString());
} catch (e) {
console.error(e);
errMsg = e.toString();
} finally {
if (resultObj && resultObj.err) {
errMsg = resultObj.err;
errMultiline = resultObj.errMultiline;
resultObj = null;
}
let end = new Date - start;
console.log('latency:', end)
}
if (errMsg) {
let err = new Error(errMsg);
if (errMultiline) {
err.vmMultilineMsg = errMultiline;
}
throw err;
}
return resultObj.output;
}This function looks really ugly. I have tried to connect to zeromq server once and then just send requests across single connection, but for some reason this approach didn't work properly and didn't re-establish connection properly in case zeromq server gone down and then back up. I have launched some basic comparison benchmarks to understand if re-connecting on every request has big overhead but it seems to add just 1-3 ms on every request which was acceptable. The best thing about this code is that it was written in an hour, it works in production, and it is fault taulerant, so downtime of extractor service won't break main ScrapeNinja logic (retrieving HTML from the target website).
Here is how the function above run in ScrapeNinja code, if we have HTML, and user has supplied extractor code, try to run extractor:
if (results.body && qs.extractor && qs.extractor.length) {
try {
results.extractor = {};
results.extractor.result = await extract(results.body, qs.extractor);
} catch (e) {
results.extractor.err = e.toString();
if (e.vmMultilineMsg) {
results.extractor.errMultiline = e.vmMultilineMsg;
}
}
}Server
Executing code in VM2
Extracting line numbers and clean stack traces from VM2 sandbox is a bit tricky and, again, ugly. And line numbers are crucial for IDE so the extractor function can be developed in any browser and the developer gets proper error line highlightning. BTW, the editor was built using Vue and CodeMirror library, but this is a topic for another blog post.
async function executeInVm(payload) {
let dumpLog = [];
// console messages from extractor function are dumped to variable
console.log = console.info = function(...args) {
dumpLog.push({ type: 'info', out: args });
consoleOriginal.log(args);
}
console.error = function(...args) {
dumpLog.push({ type: 'error', out: args });
consoleOriginal.error(args);
}
console.warn = function(...args) {
dumpLog.push({ type: 'warn', out: args });
consoleOriginal.warn(args);
}
const vm = new VM({
timeout: 1000,
allowAsync: false,
sandbox: {
cheerio, // cheerio object is available for extractor function
input: payload.input
}
});
// make console object read-only
vm.freeze(console, 'console');
try {
// run the code!
let res = vm.run(`(${payload.extractor})(input, cheerio)`);
return { output: res, log: dumpLog };
} catch (err) {
let errDescr = err.toString();
let errMultiline = null;
let errLineNumber, errLinePos = null;
let pathToHide = process.env.PWD;
// line number extraction is much harder than it needs to be
if (err.stack && err.stack.indexOf('vm.js') !== -1) {
let parts = err.stack.split('\n')[0].split(':');
let lineNumberStr = parts[parts.length - 1];
errLineNumber = parseInt(lineNumberStr, 10);
if (!errLineNumber) {
//ReferenceError
let parts2 = err.stack.split('\n')[1].split(':');
let lineNumberStr2 = parts2[parts.length - 1];
errLineNumber = parseInt(lineNumberStr2, 10);
}
}
// cleanup stacktrace a little bit...
if (err.stack && err.stack.indexOf('vm.js') !== -1) {
errMultiline = err.stack.replaceAll(pathToHide, '').replaceAll('/node_modules/vm2', '');
}
consoleOriginal.error(err.stack);
return { err:
{ msg: errDescr, msgMultiline: errMultiline, lineNumber: errLineNumber } };
}
}The result
The primary moto for my SaaS products new feature release cycle is "build quick&dirty code to achieve best results, then analyze and improve iteratively if customers (or myself) like and use the feature". Over the years it became apparent that too much preliminar analysis does more harm than good, and crappy code doing useful things is much better than perfect code which is not used by anyone. My current VM2 + docker setup for untrusted JS is not optimal in terms of code, performance, security, but it gets the job done and it's uglyness and complexity is clearly separated in separate service which can be safely disabled or later refactored.
ScrapeNinja got huge upgrade in terms of scraper development UX. I can now build robust full-fledged scraper which extracts JSON data from (almost) any HTML page, in 15 minutes instead of an hour. The process is:
- retrieve target website HTML from specific URL (via Chrome Dev Tools) and
- put the HTML in ScrapeNinja Cheerio Sandbox . Cheerio code development always requires tens and hundreds of test runs across different HTML pages of the website so the ability to have cheerio running by just opening Cheerio sandbox in a browser is a big relief for quick testing.
- after you are happy with results in Cheerio Sandbox, copy&paste the JS code of the extractor into real network request pipeline to the target website through Scraper Sandbox and now test the two processes (retrieving HTML and extracting data) combined
- Copy&paste generated Node.js code of the scraper into your Javascript project or just embed the API request to ScrapeNinja into your low-code or no-code environment.
Let me know if you have feedback or any questions:
Via email contact@scrapeninja.net or via Telegram: https://t.me/scrapeninja