Clickhouse as a replacement for ELK, Big Query and TimescaleDB
Table of Contents
UPD 2020: Clickhouse is getting stronger with each release. We are using Clickhouse as an ELK replacement in our ApiRoad.net project - API marketplace with ultimate observability and analytics of HTTP requests.
Clickhouse is an open source column-oriented database management system built by Yandex. Clickhouse is used by Yandex, CloudFlare, VK.com, Badoo and other teams across the world, for really big amounts of data (thousands of row inserts per second, petabytes of data stored on disk).
Qwintry started using Clickhouse in 2018 for reporting needs, and it deeply impressed us by its simplicity, scalability, SQL support, and speed. It is so fast that it looks like magic.
Simplicity
Clickhouse is installed by 1 command in Ubuntu.
If you know SQL - you can start using Clickhouse in no time. It does not mean you can do "show create table" in MySQL and copy-paste SQL to Clickhouse, though.
There are substantial data type differences on table schema definitions, comparing to MySQL, so it will require some time to alter table definitions and explore table engines to feel comfortable.
Clickhouse works great without any additional software, but ZooKeeper needs to be installed if you want to use replication.
Analyzing the performance of queries feels good - system tables contain all the information and all the data can be retrieved via old and boring SQL.
Performance
Benchmark against Vertica and MySQL
Cloudflare post about Clickhouse
Benchmark against Amazon RedShift [2]
Maturity
Clickhouse development happens on Github repo, at an impressive pace.
Popularity
Clickhouse popularity seems to grow exponentially, especially in the Russian-speaking community. Recent Highload 2018 conference (Moscow, 8-9 nov 2018) showed that such monsters as vk.com and Badoo are using Clickhouse in production and inserting data (e.g. logs) from tens of thousands of servers simultaneously ( https://www.youtube.com/watch?v=pbbcMcrQoXw - sorry, Russian language only).
Use cases
After I've spent some time on research I think there is a number of niches where Clickhouse can be useful and may even replace other, more traditional and popular solutions:
Augment MySQL and PostgreSQL
We've just replaced (partially) MySQL with ClickHouse for Mautic newsletter platform ( https://www.mautic.org/ ) which due to (questionable) design choices logs each email it sends, and every link in this email with big base64 hash to the huge MySQL table (email_stats). After sending mere 10 million emails to our subscribers this table easily takes 150GB of file space and MySQL starts to feel bad on simple queries. To fix the file space issue we successfully used InnoDB table compression which made the table 4 times smaller, but it still does not make a lot of sense to store more than 20-30 millions of emails in MySQL just for read-only historical information, since any simple query that for some reason has to do full scan leads to swapping and big I/O load - so we were getting Zabbix alerts all the time.
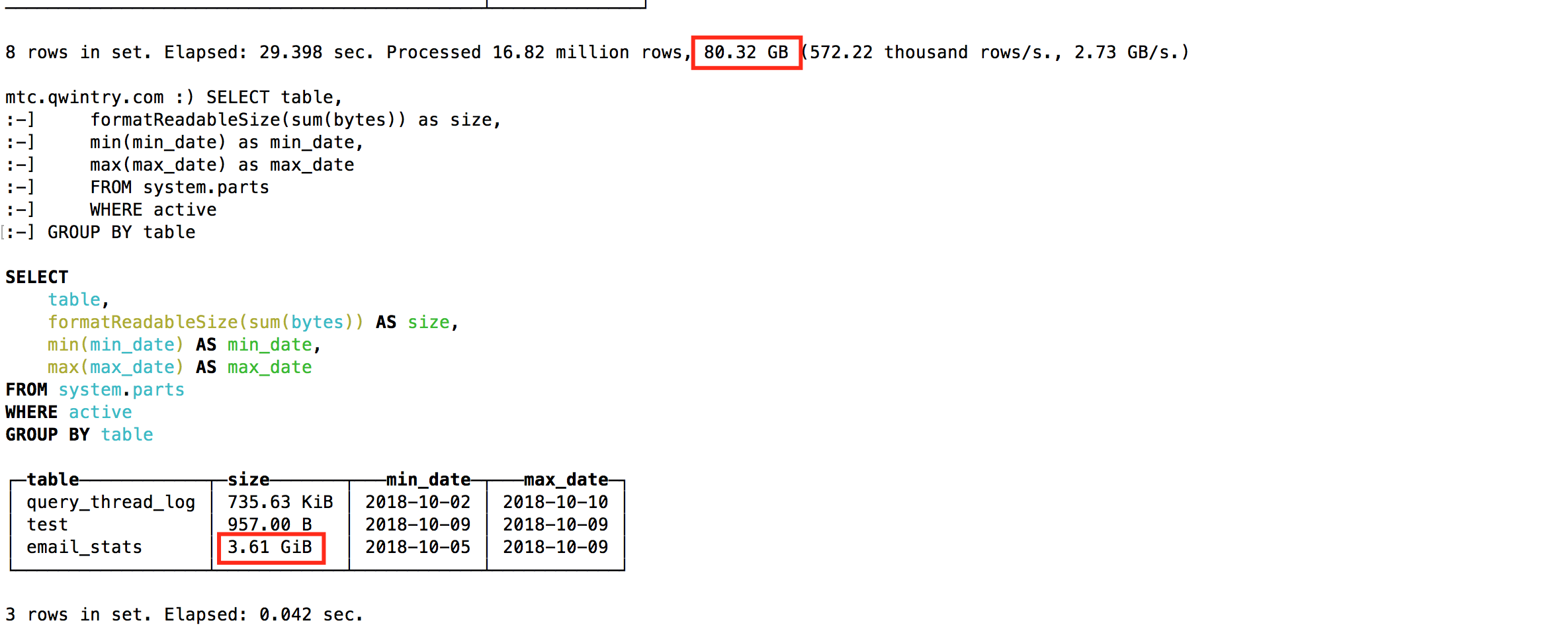
Clickhouse uses two compression algorithms, and typically the compression is closer to 3-4 times but is this specific case the data was very compressible.
Replace ELK
From my experience, ELK stack (Elasticsearch in particular) takes far more resources to run than it should when we talk about log storage purposes. Elasticsearch is a great engine if you need good full-text search (do you need full text search on your logs? I don't), but I wonder why it became de-facto standard for logging purposes - its ingestion performance, combined with Logstash, gave us troubles even on pretty small loads, and required adding more and more RAM and disk space. Clickhouse as a DB layer is better than ElasticSearch:
- SQL dialect support
- Much better compression of stored data
- Regex search support instead of full text
- Better query plans and overall performance
The biggest issue that I see now with Clickhouse (vs ELK) is the lack of log shipping solutions and documentation/tutorials on this topic (everyone can setup ELK by Digital Ocean manual, which is a huge thing for rapid technology adoption). So, the DB engine is here, but there is no Filebeat for Clickhouse yet. Yes, there are fluentd and loghouse, and there is https://github.com/Altinity/clicktail, but more time is required so the simple and best way takes the strong lead so newcomers just install and use it in 10 minutes.
Since I like minimalistic solutions I tried to use FluentBit (which is a log shipper with very small memory footprint) with Clickhouse (and I tried to avoid using Kafka in between) but small incompatibilities like date format issues still need to be figured out before this can be done without proxy layer which converts data from Fluentbit to Clickhouse.
Talking about Kibana alternative - there is Grafana which can be used with Clickhouse as backend. As far as I understand there may be issues with performance when rendering huge amount of data points, especially with older Grafana versions - at Qwintry we haven't tried it yet, but complaints about this appear from time to time in Clickhouse telegram support channel.
Replace Google Big Query and Amazon RedShift (for bigger companies)
A perfect use case for Big Query is: upload 1TB of JSON data and run analytical queries on it. Big Query is a great product and it's hard to overestimate its scalability. It is a lot more sophisticated piece of software then Clickhouse running on an in-house cluster, but from the customer point of view, it has a lot of similarities with Clickhouse. Big Query can quickly get pricey since you pay for each SELECT, and it is a SaaS solution with all its pros and cons.
Clickhouse is a great fit if you run a lot of computationally expensive queries. The more SELECT queries you run every day - the more sense it has to replace Big Query with Clickhouse - it may literally save you thousands of dollars if we talk about many terabytes of processed data (not stored data, which is pretty cheap in Big Query).
Altinity summed it up well in "Cost of Ownership" section in their article.
Replace TimescaleDB
TimescaleDB is a PostgreSQL extension, specializing in timeseries data.
https://docs.timescale.com/v1.0/introduction
Clickhouse did not really start to seriously compete in the time-series niche, but due to its columnar nature and vectorized query execution it is faster than TimescaleDB in most of the analytical queries, batch data ingestion performance is ~3x better and Clickhouse uses 20 times less disk space which is really important for big amounts of historical data:
https://www.altinity.com/blog/clickhouse-for-time-series
The only way to save some disk space when using TimescaleDB is to use ZFS or similar file system.
Upcoming updates to Clickhouse will most likely introduce delta compression which will make it even better fit for time-series data.
TimescaleDB may be a better choice than (bare) Clickhouse for:
- small installations with very low amount of RAM (<3 GB),
- big amount of frequent small INSERTs which you don't want to buffer into bigger chunks.
- better consistency and ACID
- PostGIS support
- tight mix and easy joins with existing PostgreSQL tables (since essentially TimescaleDB is PostgreSQL)
Compete with Hadoop and MapReduce systems
Hadoop and other MapReduce products can do a lot of complex calculations, but these tend to have huge latencies, and Clickhouse fixes it - it processes terabytes of data and gives results almost instantly. So for rapid, interactive analytical research Clickhouse can be a lot more interesting for data engineers.
Compete with Pinot and Druid
Closest contenders (column-oriented, linearly scalable, open source) are Pinot and Druid, there is a wonderful write-up with comparison here:
https://medium.com/@leventov/comparison-of-the-open-source-olap-systems-for-big-data-clickhouse-druid-and-pinot-8e042a5ed1c7
The article is a bit updated: it states that Clickhouse does not support UPDATE and DELETE operations, which is not exactly the case for latest versions.
We do not have any experience with these, but
I don't like the complexity of infrastructure that is required to run Druid and Pinot - big amount of moving parts, and Java everywhere.
Druid and Pinot are Apache incubator projects and their GitHub pulse pages show good development pace. BTW, Pinot went for Apache Incubator just a month ago - in October of 2018. Druid went for Apache Incubator just 8 months earlier on 2018-02-28.
This is really interesting and raises some (stupid?) questions because I have very little information on how ASF works.
Did Pinot authors notice that Apache Foundation is giving a lot of acceleration to Druid and felt a bit envious? :)
Will it somewhat slow down Druid and accelerate Pinot development (of course if there is a phenomenon of volunteer contributors which were committing to Druid but suddenly got interested in Pinot)?
Clickhouse CONS
Immaturity
This is obviously not a boring technology yet (but there are no such thing in columnar DBMS, anyways)
Small inserts at high rate perform poorly
Inserts need to be batched into bigger chunks, the performance of small inserts degrades proportionally to a number of columns in each row. This is just how data is stored on disk in Clickhouse - each column means 1 file or more, so to do 1-row insert containing 100 columns at least 100 files needs to be opened and written to. That's why some mediator is required to buffer inserts (unless the client can't buffer it) - usually, Kafka or some queue system. Or, Buffer table engine can be used and data can be copied to MergeTree tables later in bigger chunks.
Joins are restricted by server RAM
Well, at least there are joins! E.g. Druid and Pinot do not have joins at all - since they are hard to implement right in distributed systems, which do not support moving big chunks of data between nodes.
Conclusion
At Qwintry, we plan to use Clickhouse extensively in the upcoming years, because it hits a great balance of performance, low overhead, scalability, and simplicity. I am pretty sure its adoption will increase rapidly as soon as Clickhouse community generates more recipes on how it can be used at small and medium-sized installations.