Blocking images in Playwright
Blocking unnecessary resources in Playwright is a pretty easy task, thanks to builtin route() function.
Table of Contents
In the summer of 2023, I had a client with a custom project where my task was to extract data from a notoriously dynamic single page application (SPA). The site was a huge bunch of JavaScript with robust anti-scraping measures. It felt like a digital game of cat and mouse, and I was the determined mouse. That's when Playwright, a framework for automated browser testing, came to the rescue. It wasn't just about rendering SPAs or managing dynamic content; Playwright excelled at bypassing JavaScript-based anti-scraping mechanisms.
I used Node.js version of Playwright (it is also available as Python package, do not confuse these two!) and stealth npm packages to blend in seamlessly, making my scraping activities indistinguishable from regular browsing. The interesting part was that I used 4g proxies to avoid getting captchas, but it made page loads very slow – so I did my best to increase the speed of page loads by blocking unneccesary media and images, and I am going to show you some code how this could be done.
Playwright: A Quick Overview
Playwright, for those who might not be familiar, is a framework for automated browser testing. But its utility extends far beyond that, especially in web scraping. I've personally found it incredibly effective in handling SPAs and navigating through complex scenarios which requires button clicking and other web page interactions – it simulates a user's interaction with a web page, making it a powerful tool for scraping dynamic content (my best one is endless scrolling!).
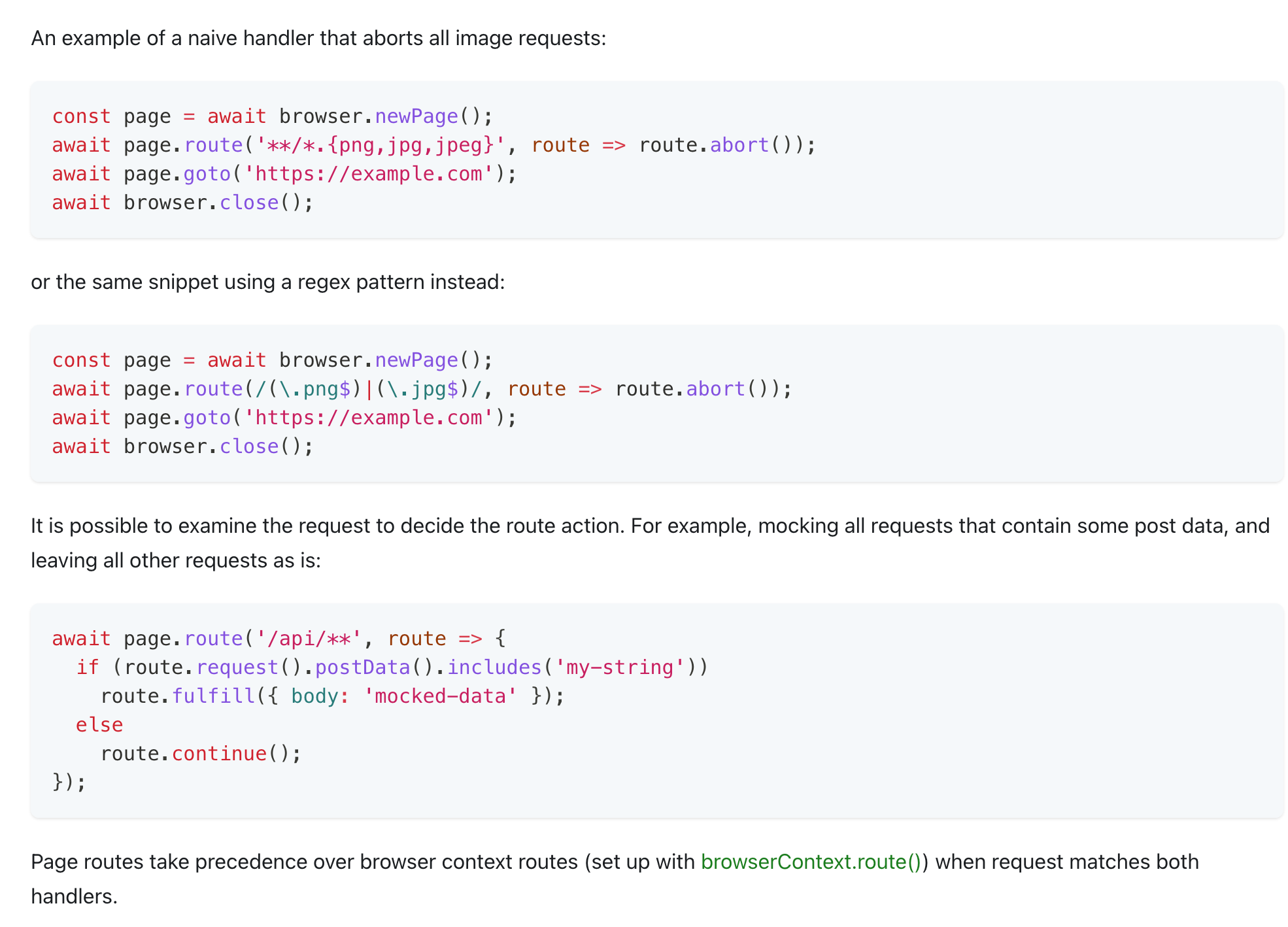
The Role of route() in Playwright
To block images on page download, you need to learn about one super-useful essential Playwright feature: route() function. This function allows us to intercept and modify network requests. In my journey with web scraping, I've used route() in various scenarios – from modifying request headers to injecting scripts. It offers an unprecedented level of control over how the browser interacts with a website, giving us the power to tailor our scraping strategy to specific needs. Compared to Puppeteer, another great Node.js package for programmatical browser control, Playwright route() function is much more concise and convenient. For example, it allows to use JS regexes out of the box! Please refer to route docs.
The Challenge: Proxies and Resource Management
As I've said, I used 4g proxies for my project. They're essential for maintaining anonymity and bypassing IP-based restrictions. However, proxies can be slow and, if you're not careful, expensive in terms of traffic. This is where resource management becomes crucial.
Blocking unnecessary resources in Playwright
In many scraping tasks, we don't need to load images, fonts, or even CSS. These resources consume bandwidth and slow down our scraping process. By blocking these resources, we can significantly speed up our scraping jobs and reduce costs.
Node.js Playwright code to block images, css, and fonts
Here's a practical example of how to implement resource blocking in Playwright. This Node.js code uses top level async/await (so please use Node.js 16+) , ES6 imports (so don't forget to use type:module in package.json of your project), and the route() function to block images, fonts, and CSS.
import { chromium } from 'playwright';
const browser = await chromium.launch();
const page = await browser.newPage();
// Use route() to intercept and block certain types of resources
await page.route('**/*', (route) => {
const resourceType = route.request().resourceType();
if (['image', 'stylesheet', 'font'].includes(resourceType)) {
route.abort();
} else {
route.continue();
}
});
// Navigate to the website
await page.goto('https://example.com');
// Perform your scraping tasks here
await browser.close();
In this code, we launch a Chromium browser, create a new page, and set up a route handler. The handler checks the resource type of each network request and aborts it if it's an image, stylesheet, or font. This significantly reduces the amount of data downloaded and processed, leading to faster and more cost-effective scraping.
Extending blocking: get rid of unneccesary tracking and JS
Let's top it up a notch and get rid of various tracking scripts which usually slow down the page loading times significantly.
import { chromium } from 'playwright';
// Using top-level async/await
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
// Define a list of common ad network patterns
const adNetworkPatterns = [
'**/*doubleclick.net/**',
'**/*googleadservices.com/**',
'**/*googlesyndication.com/**',
// Add more patterns as needed
];
// Use route() to intercept and block certain types of resources and ad network requests
await page.route('**/*', (route) => {
const requestUrl = route.request().url();
const resourceType = route.request().resourceType();
// Check if the request is for an ad network
const isAdRequest = adNetworkPatterns.some(pattern => requestUrl.match(pattern));
if (['image', 'stylesheet', 'font'].includes(resourceType) || isAdRequest) {
route.abort();
} else {
route.continue();
}
});
// Navigate to the website
await page.goto('https://example.com');
// Perform your scraping tasks here
await browser.close();
})();
Conclusion
Playwright's flexibility, particularly with functions like route(), makes it an incredible tool for web scraping and automation. By understanding and leveraging these capabilities, we can efficiently navigate through the complexities of modern web applications. Remember, in the world of web scraping, it's not just about getting the data; it's about getting it efficiently and responsibly. Keep exploring, and happy scraping!