Choosing a proxy for web scraping

Table of Contents
Once you're familiar with basic web scraping tools like Scrapy, and you've scraped your first 1-2 websites, you'll probably get your first ban because your IP address has made too many requests (what "too many" means really depends on the site, for one site it's just 3 requests per hour, for another site it's 100 requests in a 5 minute window). It's important to make sure that the site ban is actually related to an ip address from which you're sending your requests: to check that it's not a cookie or some browser fingerprinting technique, try scrambling the same target from a different browser but from the same ip address.
Once you're sure that it's your IP address that's causing the problems, you'll probably need to think about getting a proxy.
Which one to choose?
What is a Proxy for Web Scraping?
In the context of data extraction, when we refer to "proxies," it's crucial to understand that we're talking about forward proxies, not reverse proxies. Reverse proxies are typically used in website building and internal network structuring, while forward proxies are our tools for web scraping.
A quick Google search for "proxy for web scraping" yields a plethora of results, demonstrating how this niche has become a battleground for both small and large players. They continuously compete, offering a variety of options and trial periods. This competition drives innovation and quality in the proxy market.
A proxy, in simple terms, is a remote machine to which you can connect. This connection allows the target website to see the HTTP request originating from the proxy, not your personal machine. This approach is essential for web scraping, as it helps in anonymizing the source of data requests and circumventing IP-based restrictions.
When I was just starting out with web scraping, I had a project where I had to scrape a major e-commerce site for market analysis. Initially, I tried to do this without a proxy, and it was a disaster. My IP got banned within hours. Then, I have tried to find a "free proxy list" in Google, and tried to use these free proxies - less than 3% of them worked, so it was a major time sink. After spending many hours on writing my Node.js proxy-checker-cli package to verify quality of these free proxies - and never getting an acceptable quality from these free proxies, I finally switched to a paid residential proxy service, and the difference was night and day. Not only could I scrape the data seamlessly, but the proxy also provided a level of reliability and speed that was crucial for the success of my project.
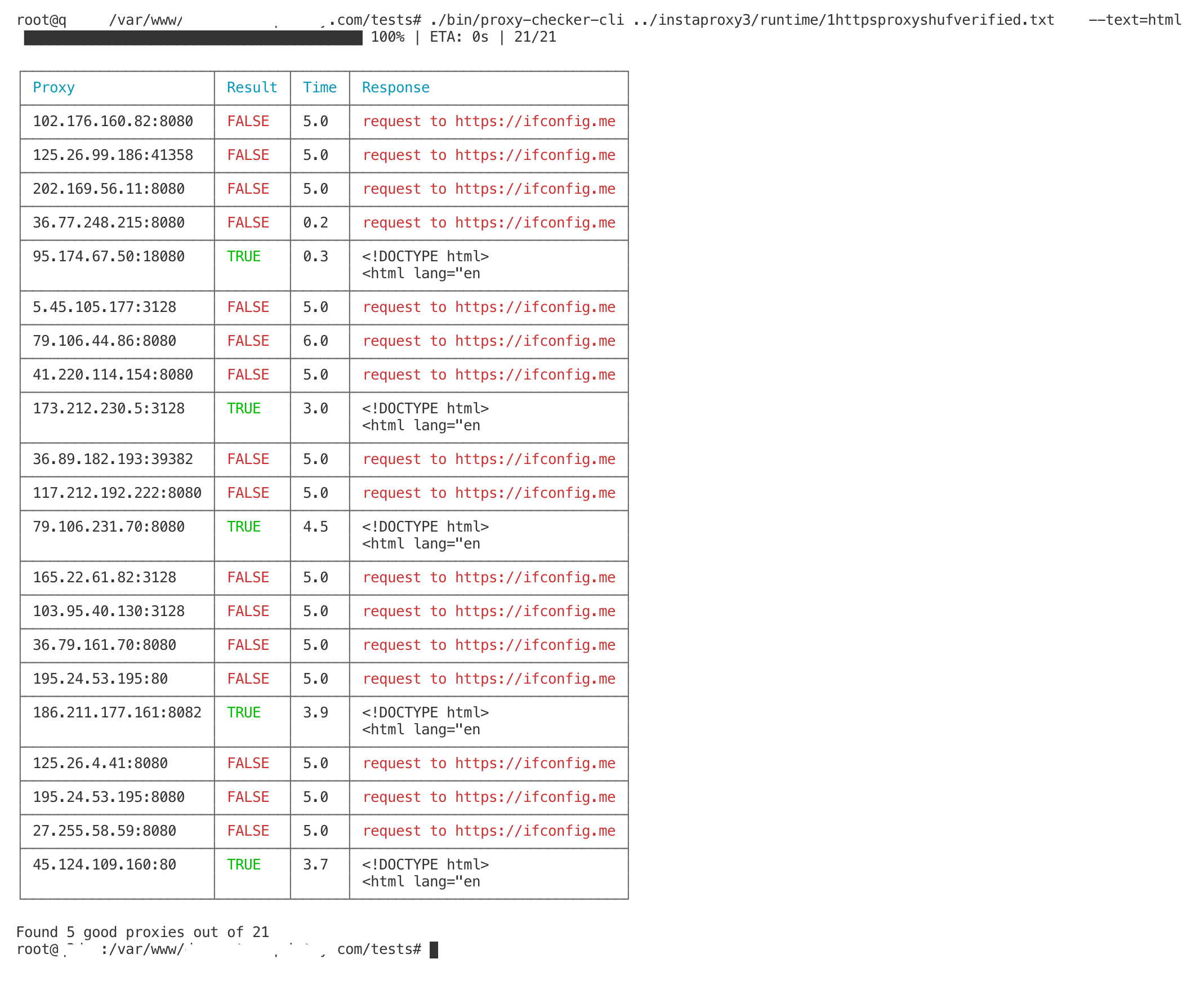
So, my first advice would be: don't spend your time on free proxies; especially the ones you found on World Wide Web. Even if you don't need highest quality. These proxies are DDoSed by bad actors and are probably just a poor hacked machines.
Several years passed, and ScrapeNinja web scraping API (this is a SaaS for web scraping which I am bootstrapping) now uses more than 10 proxy providers under the hood, so I know a thing or two about proxies now!
We can classify proxies available on the market based on various characteristics, such as their IP reputation, speed, reliability, and cost. Each type has its unique advantages and fits different scraping needs.
Proxies by Address Type: Residential vs Mobile vs Datacenter vs Internet Provider
Residential and Mobile Proxies
- Typically have the highest IP reputation.
- Most expensive option.
- Ideal for tasks that require a high degree of legitimacy, such as ad verification or market research.
- Can be slower and less suitable for bulk operations due to their higher cost.
The difference between residential and mobile is that mobile ip address has the highest possible reputation, as mobile providers usually use CGNAT technology, so there are multiple real customers behind each ip address, so it's a normal thing to get a lot of HTTP requests from single ip address if this ip range belongs to a cell phone network provider. Also, in a lot of cases, private mobile proxies are often sold by port, so you can change ip address of this proxy by calling a special link which technically reboots a modem with this sim card.
Datacenter Proxies
- Usually the cheapest and fastest proxies.
- Often have the lowest reputation, leading to frequent bans by many websites.
- Not suitable for long-term or sensitive tasks.
- An example of their limitation is the blacklisting of certain IP ranges, like those from Hetzner.
Internet Provider Proxies
- Provide a balance between cost and IP reputation.
- Less expensive than residential proxies but more reliable than datacenter proxies.
- Commonly used for tasks like general web scraping or SEO monitoring, where high IP reputation is not critical.
By access type: private vs semi-private vs shared
This usually refers to mobile proxies. Some proxy providers guarantee that you are the only one using the proxy. This means that the proxy is private. "Shared" access mode means that many customers of the proxy provider can use the same proxy at the same time, potentially interfering with each other in terms of IP reputation.
"Semi-private" is an interesting cost optimisation approach where the proxy provider guarantees that only you will be able to access a particular website through that proxy. At the same time, another customer can use the same proxy to access a different target website. These "semi-private" mobile proxies are usually cheaper and can still maintain good performance.
By billing type: traffic based vs unlimited
One of proxy provider distinctive traits is how you are going to be charged. Are you going to be charged by traffic, per GB? Or unlimited? Most of residential proxy networks are charged by GB. Most of datacenter proxies are charged "per-ip". But of course it depends on particular proxy provider.
By protocol: SOCKS5 vs HTTP(S) proxies
You need to make sure that your web scraping tool can work with a protocol your proxy provider offers to you. SOCKS5 is a lower level (TCP) protocol, and HTTP is a higher level protocol.
Most of modern web scraping tools and frameworks can work both with socks and http(s) proxies.
By anonymity
The level of anonymity a proxy provides is crucial for web scraping and other online activities where privacy is a concern. Proxies can be categorized based on their anonymity level, which ranges from transparent to elite. Transparent proxies offer the least anonymity as they pass your original IP address in the HTTP headers. Anonymous proxies, on the other hand, do not reveal your IP address but can disclose that a proxy is being used. Elite proxies provide the highest level of anonymity, concealing both your IP address and the use of a proxy.
A key component in the anonymity provided by proxies is the X-Forwarded-For header. This HTTP header field is used to identify the originating IP address of a client connecting through an HTTP proxy or load balancer. While paid proxies for web scraping usually do not include this header, thereby masking the originating IP, transparent proxies may include the client's IP address in this header.
How to verify if http proxy is anonymous
The easy way to verify if the proxy is not passing additional headers is to make a request to some website which dumps all headers of the connection:
curl -x http://192.0.2.1:8080 http://httpbin.org/anything
httpbin.org will respond with JSON containing all the headers which you sent to it:
{
"args": {},
"data": "",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Cache-Control": "max-age=259200",
"Host": "httpbin.org",
"User-Agent": "curl/7.58.0",
"X-Amzn-Trace-Id": "Root=1-65ad06d1-460b433a674a654d292015d4"
},
"json": null,
"method": "GET",
"origin": "191.101.33.56",
"url": "http://httpbin.org/anything"
}If you notice X-Forwarded-For header in .headers of httpbin response, this means this proxy is "transparent" and passes your address along with its request to target website.
Anonymity: HTTP vs SOCKS proxies
Another aspect of anonymity relates to the type of proxy protocol used: SOCKS versus HTTP proxies. SOCKS proxies, particularly SOCKS5, are considered more secure and anonymous compared to HTTP proxies. This is because SOCKS5 proxies, by design, do not interpret the network traffic between your device and the server, which means they do not rewrite header data. This makes them suitable for handling any type of traffic or protocol, not just web browsing, without the risk of exposing your IP address.
SOCKS proxies operate at a lower level (TCP) compared to HTTP proxies, and they simply relay the traffic between the client and the server without inspecting or modifying the network traffic content.
HTTP proxies, in contrast, can interpret network traffic and are limited to web browsing activities. They are less secure in terms of anonymity as they can potentially reveal more information about the client to the server. However, for tasks strictly related to web browsing, they can be more efficient.
Finally, the choice between using a SOCKS or HTTP proxy can also influence the level of anonymity. SOCKS proxies, due to their lower-level operation (operating at the TCP level), can handle a broader range of traffic types without revealing your IP address. HTTP proxies, while more limited in scope, can provide adequate anonymity for web browsing if configured correctly. The choice between the two will depend on the specific requirements of the user and the nature of the tasks they intend to perform.
When you purchase proxies for web scraping, even HTTP proxies will be anonymous by default, the only SOCKS proxy advantage here is that this anonymity is explicit: there is simply no way for SOCKS proxy to pass any data regarding the origin of the request, to the target website.
Proxies by rotation: on every request vs schedule
There is a big number of companies who sells proxies for web scraping.
You might need a different type of proxy for various web scraping tasks: for example, if you are scraping anonymously, you should prefer a rotating proxy (a proxy where each HTTP request goes from a new ip address); if you are scraping as a logged in user - you should prefer dedicated ip proxy or sticky session proxy.
Static Address Proxies
Static proxies are usually sold "per ip". You just get one ip address. It has limited value for anonymous web scraping - once this ip address is banned, you can't use it anymore for this website. But, it can still be useful for long authenticated sessions on a website.
Rotating Proxies
Rotating proxies are further divided into various types: for example, some of rotating proxies are rotated on every request; other proxies are rotated on a time basis, for example every 5 minutes.
Sticky session proxies
Sticky session proxies use a hybrid approach. Here is how it works: you pass a random seed into proxy credentials (usually, username), like this:
# KEY is your session key
curl -x http://proxy-username-session-KEY:password@proxy-provider:333 https://example.comNow, if you pass the same "KEY", you will always get the same proxy ip address, but as soon as you pass "NEW-KEY", you will get another proxy ip address. This way, you can have multiple "sessions" which might be very useful for authenticated scraping sessions.
How "Smart Proxies" work: subtle and important difference compared to regular proxies
Some of bigger web scraping players have recently started offering "smart proxies". Here is an example: BrightData Web Unlocker
It features:
- Bypass CAPTCHAs, blocks, and, restrictions
- Only pay for successful requests
- Automated IP address rotation
- User emulation & fingerprints
The integration example shows that it can be used via dumb cURL utility:
curl --proxy brd.superproxy.io:22225 --proxy-user brd-customer-hl333:password -k "http://lumtest.com/myip.json"The most important thing here is the -k flag. It allows for the magic to happen, but to explain how it works we need to understand how basic HTTP proxies work when you are connecting to a https website:
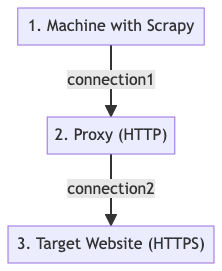
99% of real-world websites you are going to scrape are https websites. When you "ask" a regular http proxy that you want it to connect to a target website on your behalf, it opens an encrypted tunnel between you and the target website.
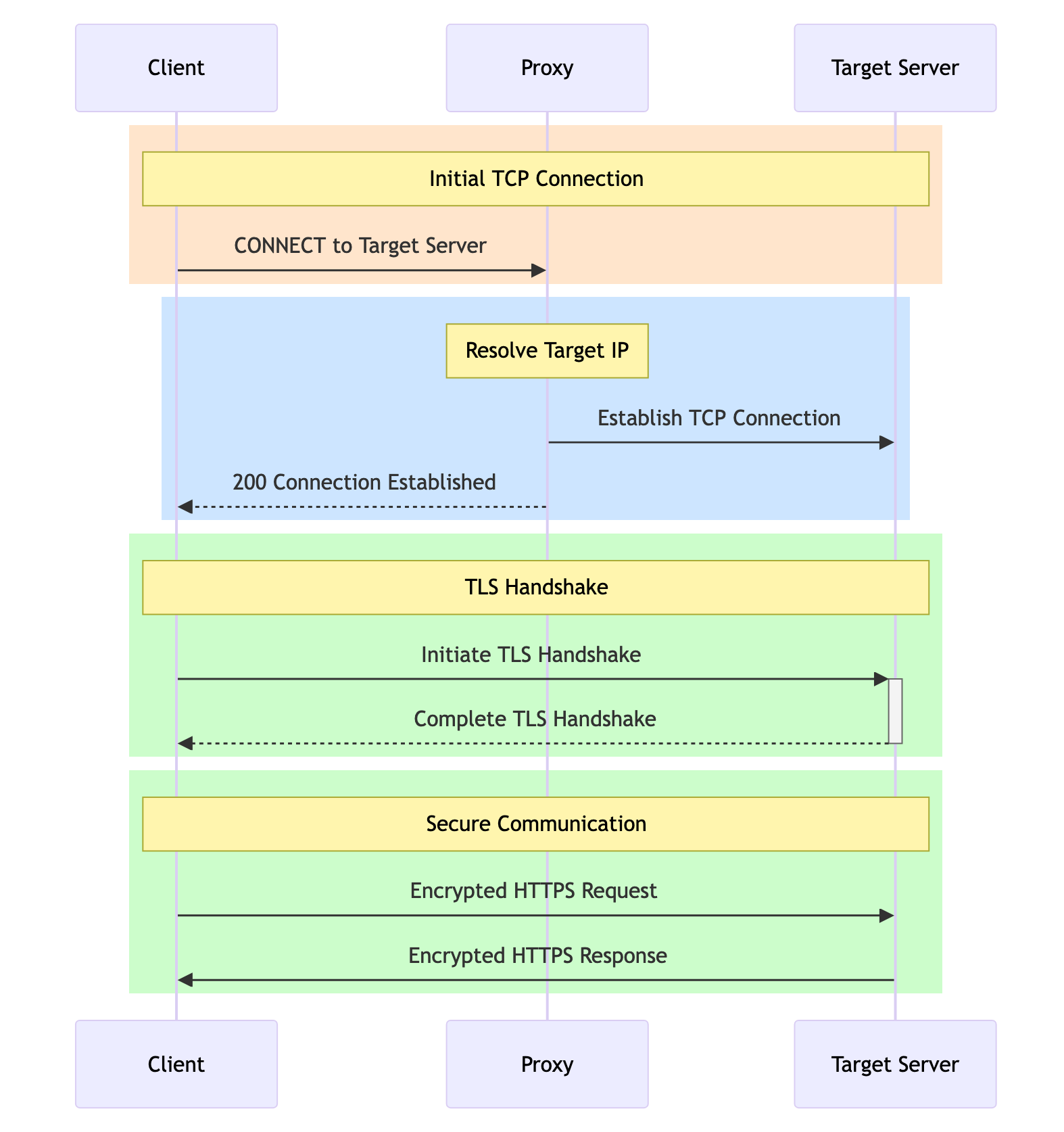
curl -x http://login:pw@proxy:port https://lumtest.com/myip.jsonA proxy does not have any control on this encrypted tunnel and can't see what you are sending to this tunnel and what you are receiving back. This proxy mode is called "the CONNECT method". Of course, if a proxy can only see the encrypted bits and bytes, it can't know that the website has shown you a captcha, right? Right. This is where -k flag steps in. This flag specified when you connect to a proxy means "I am ok that proxy can see all the traffic flowing through the proxy". This has significant cons and pros - pros are listed above, proxy can now "retry" based on something it saw in your traffic. And cons are obvious, too: now proxy provider can see all the data you send to the target website and back. Another con is that "smart proxy" is usually significantly more expensive than regular proxy.
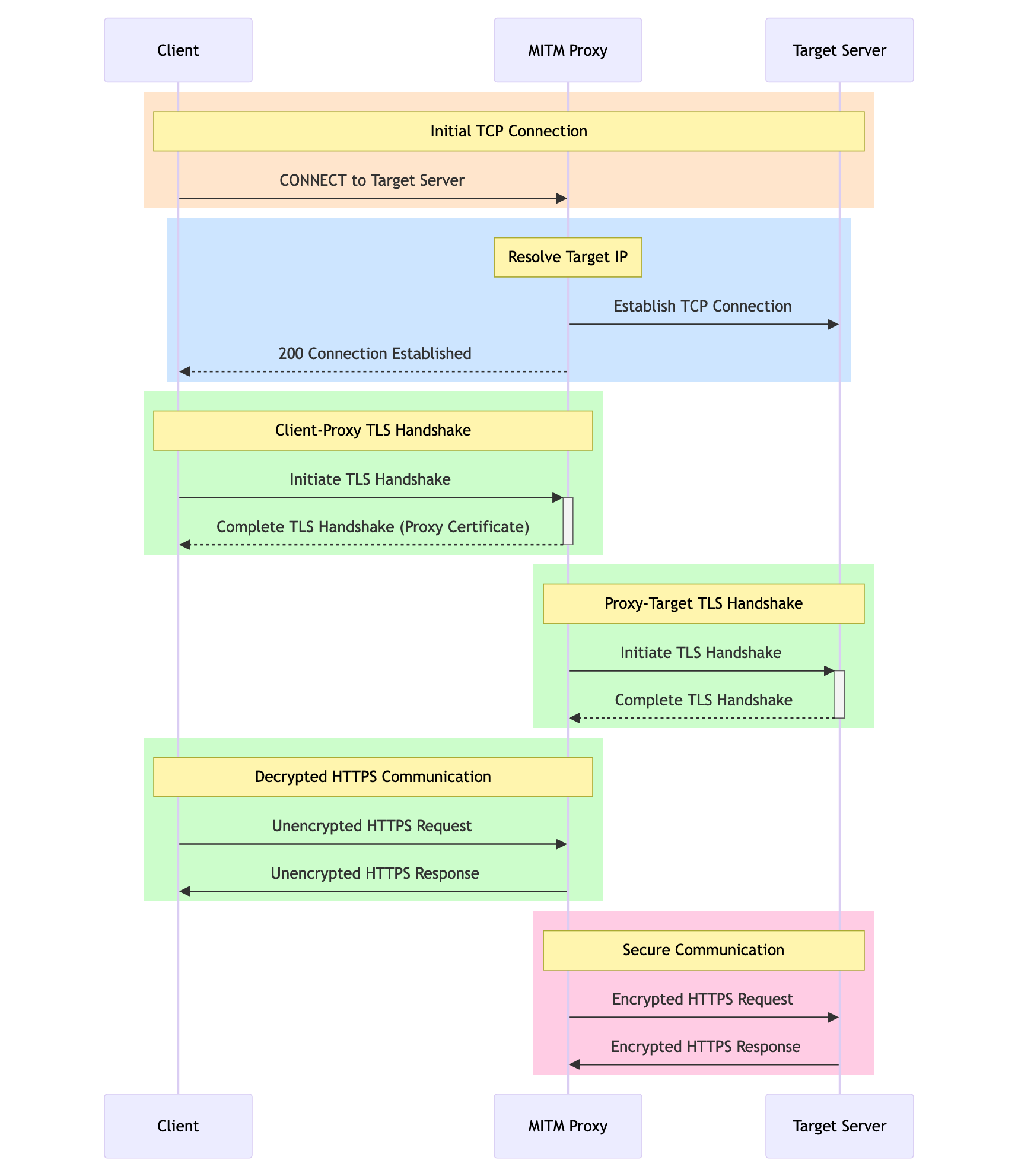
For a lot of web scraping tasks, that's perfectly OK, especially considering that Smart Proxy can be a great way to hide the complexity of retries and captcha solving and do it transparently for the Client – what surprises me is that not a lot of consumers realize this subtle difference between proxy types.
How to use proxy in cURL
Of course, cURL is a perfect terminal utility I recommend to start with, when you are trying to verify how your proxies behave. cURL has two syntaxes to specify proxy.
- first syntax:
curl -x http://user:pw@proxy-addr:port https://example.com - second syntax:
curl --proxy proxy-addr.com:port --proxy-user proxy-user:password https://example.com
I prefer shorter -x syntax.
How do I check the proxy's current IP address and country?
To see what what is the proxy current ip and geo, I recommend to use https://lumtest.com/myip.json as a target url, it outputs all the information is a convenient JSON syntax:
{"ip":"167.235.139.77","country":"DE","asn":{"asnum":24940,"org_name":"Hetzner Online GmbH"},"geo":{"city":"Hachenburg","region":"RP","region_name":"Rheinland-Pfalz","postal_code":"57627","latitude":50.6584,"longitude":7.8268,"tz":"Europe/Berlin","lum_city":"hachenburg","lum_region":"rp"}}Typing these cURL commands and lumtest.com URL every time can get a bit tedious. So I wrote a simple bash script that I use on my Linux machines to quickly check if the proxy is working. Here is the blog post about the simple terminal proxy checker utility.
If you enjoyed this article, check my blog posts on how to set proxy in Playwright and how to set proxy in Python Requests.
Good luck choosing and using your proxies!